This document (notebook) presents a computational approach to identifying outliers in a set of multidimensional (geometric) points. The method discussed and demonstrated is based on nearest-neighbor statistics. Related workflow extensions, such as visualization and classification, are also shown.
The Python package “GeometricNearestNeighborsProcessor”, [AAp1], is used (which, as the name indicates, was specifically developed for tackling these kinds of problems.)
Purpose and theoretical background
Consider the following computational tasks for a given set of n-dimensional (nD) points P:
Find the points of P that are outliers or anomalies
Find the points of another set P1 that can be seen as anomalies wrt to P
For a given nD point s find its Nearest Neighbors (NNs) in
The points of can have labels
It might be desired to get the distances and labels of the NNs of s
Plot the points P with minimal setup or specification writing
Give the (sparse) proximity matrix of for a specified number of neighbors
Let us define an anomalous point as one that is “too far” from the other points. Which points are “too far” from the rest can be determined by examining statistics of distances between each point and nearest neighbors of it.
More concretely, point anomalies are found in the following way:
Input:
Points P as a data frame, list, or dictionary
Number of nearest neighbors n
Distance function d
Aggregation function a
For each point of P
Find its n nearest neighbors
Aggregate with a the corresponding n distances
Using the statistics from the previous step — a 1D array — find outlier identification parameters
Like, Hampel-, SPLUS-, or Quartile parameters
Identify anomalies using the parameters of the previous step
Setup
Here are imported (and aliased) the packages used below:
For some of the algorithms for recommendations systems or search engines it is helpful to have a metrics of the distances from each point to its top-K nearest neighbors. We call that matrix “proximity matrix”. Here is the proximity matrix of the GNN object created (and trained) above:
# <Compressed Sparse Row sparse matrix of dtype 'float64'
with 330 stored elements and shape (30, 30)>
Here is a corresponding matrix plot:
rows,cols=mat.nonzero()
fig=go.Figure(data=go.Scattergl(
x=cols,
y=rows,
mode='markers',
marker=dict(size=3)
))
fig.update_layout(
title="Proximity matrix",
xaxis_title="Columns",
yaxis_title="Rows",
yaxis_autorange='reversed',
xaxis=dict(scaleanchor='y',scaleratio=1),
yaxis=dict(constrain='domain'),
width=600,
height=600,
template="plotly_dark"
)
fig.show()
Additional comments
The package “GeometricNearestNeighborsProcessor” provides the class GeometricNearestNeighborsProcessor that can be used to construct chainable, monadic pipeline-like behavior.
Plotting of the data points is done via “plotly” — just a scatter plot of 2D points for now.
The chainable behavior of the methods of the class GeometricNearestNeighborsProcessoris implemented by following the principle that all methods return self, except the so-called “takers”.
This document (notebook) discusses the Python package “DSLExamples”, [AAp1], which is a “data package” with examples of DSL commands translations to programming code. The DSL examples are suitable for LLM few-shot training.
The function llm_example_function provided by “LLMFunctionObjects”, [AAp2], can be effectively used to create translation functions utilizing those examples. The utilization of such LLM-translation functions is exemplified below. A table with the results of correctness and speed experiments is also shown.
Similar translations — with much less computational resources — are achieved with grammar-based DSL translators; see the Raku package “DSL::Translators”, [AAp2]. The Raku package “LLM::Resources”, [AAp4], has LLM-graphs for code generation that utilize the DSL examples of this package.
Note that for dsl_examples the language to translate from is specified. Currently, the package has DSL examples for Bulgarian, English, Portuguese, and Russian (being from-languages.)
Get the examples for Latent Semantic Analysis (LSA) Monadic pipeline segments in Python:
# Secondary testing function (for ≈ 1/4th of the models)
llm_pipeline_segment=llm_example_function(dsl_examples('WL','LSAMon'),llm_evaluator=conf,prompts='Do the generation by example as quickly as possible. Do not overthink it.')
A few observations:
For a few of the models the secondary function produced different results, but for most not difference in results and timings were observed.
For some of the models that produced a correct results multiple executions were made and occasionally different (and wrong) code was generated.
The tests are for line-by-line generation; en-bloc tests can produce different results.
Hopefully, fast and correct.
Of course, a more extensive benchmark study can be staged for different combinations of models, programming languages, natural languages, and workflows.
But that would require more planning, time, and resources.
Provider
Model
Approx. Time, s
Approx. Time, m
InWords
Success
Comments
Ollama
gemma4:26b
240
4
Very slow
Correct
Ollama
gemma4:26b
190
3.2
Very slow
Correct
max_tokens = 500
Ollama
gemma4:26b
240
4
Very slow
Wrong
with the do-not-overthink-it prompt
Ollama
gemma3:12b
240
4
Very slow
Wrong
generates lots of redundant code and explanations
Ollama
qwen3-coder:30b
25
0.5
Fast
Wrong
generates a bunch of explanations
Ollama
gpt-oss:20b
90
1.5
Slow
Wrong
generates a bunch of explanations
Ollama
qwen3.5:9b
630
10.5
Very, very slow
Correct
Correct code followed by a Markdown table
Ollama
qwen3.6:35b
480
8
Very, very slow
Correct
Ollama
qwen3.6:35b
300
5
Slow
Correct
with the do-not-overthink prompt
Ollama
llama3.2:latest
25
0.5
Fast
Wrong
generates a bunch of explanations
Ollama
gemma3:1b
15
0.4
Fast
Wrong
Ollama
gemma3:4b
60
1
Slowish
Wrong
generates a bunch of code
Ollama
deepseek-r1:latest
250
4.5
Slow
Wrong
generates a bunch of explanations and JSON structures
“Chatnik” is a Python package that provides Command Line Interface (CLI) scripts for conversing with multiple, persistent Large Language Model (LLM) personas. Files of the host Operating System (OS) are used to maintain persistence.
Most importantly, “Chatnik” does not try to entrench users in its own user experience (loop) for interaction with LLMs. Instead, it brings customizable LLM invocations and conversations into the Unix shell — making them composable, integratable, and scriptable with existing workflows.
In other words, the tag line “LLM Host in the Shell” should be understood as “LLMs, not as an app — but as a Unix shell primitive.”
Here are the most notable “Chatnik” features:
Provides UNIX shell pipelining for LLM interactions
Maintains a database of LLM chat objects
Connects to multiple models across different LLM providers
Offers access to a large repository of prompts
Enables convenient retrieval of interaction history
Includes management tools for the LLM chat object database
Preprocesses prompts using a simple domain-specific language (DSL)
Supports loading user-defined LLM personas from JSON files
Remark: “Chatnik” closely follows the LLM-chat objects interaction system of the Python package “JupyterChatbook”, [AAp3].(Using OS shell instead of Jupyter notebooks.)
Remark: The Raku package “Chatnik” was ported to the Python package “Chatnik”. While the interface remains the same, the Raku CLI commands use kebab-case (llm-chat and llm-chat-meta) and in Python they were switched to snake_case (llm_chat and llm_chat_meta.)
Remark: Based on the previous remark, much of this document should be understood as describing the “Chatnik system” rather than a specific Python package.
The rest of this document is organized as follows:
Introductory examples
Why make another LLM-CLI system?
Architectural design
Related and alternative packages
Introductory examples
The examples in this section demonstrate how the CLI scripts llm_chat and llm_chat_meta — provided by “Chatnik” — are used to have multi-turn LLM conversations and compose Unix shell pipelines with LLM interaction messages.
Remark: The prompts used in the examples are provided by the Python package “LLMPrompts”, [AAp2]. Since many of the prompts of that package have dedicated pages at the Wolfram Prompt Repository (WPR) the examples use WPR reference links.
Chat with Yoda
Here we create an LLM persona — by naming it and “priming it” with a prompt — and start interacting with it:
llm_chat --chat-id=yoda --prompt=@Yoda 'Hi! Who are you?'
Hmmm. Yoda, I am. Jedi Master wise and old, yes. Guide you, I will, if open to the Force you are. Hmm. Help you, how can I?
Here we continue the conversation — using the -i synonym of --chat-id and no-quotes message argument:
llm_chat -i=yoda How many students did you have
Many, my students were. Count them, difficult it is. Fifty years or more, I trained Jedi young and old. Luke Skywalker, one of my greatest, yes. Strong in the Force, he became. Hmmm. Learn more, do you wish?
And continue the discussion some more:
llm_chat -i=yoda 'Which student is the best?'
Best, difficult to say it is. Each student, unique in their path they are. Luke Skywalker, strong and brave, he was. Anakin Skywalker, powerful but troubled, yes. Judge not by strength alone, you must. Wisdom, patience, and the light within, important they are. Hmm. Feel the Force, you do?
The example used the LLM persona “Yoda”. (See more LLM personas here.)
Fortune-echo-limerick pipeline
Here we specify a pipeline for
Getting a fortune
Echoing it
Using the fortune to make a limerick
fortune | tee /dev/tty | llm_chat --prompt="Make a limerick from the given text:"
Real Time, adj.:
Here and now, as opposed to fake time, which only occurs there and then.
There once was a term called “real time,”
Meaning “now,” not some past tense or mime.
Not “there” and not “then,”
But right here, right when—
The present, in rhythm and rhyme.
Remark: In the shell command above, llm_chat created (or reused) a chat object with the default identifier “NONE”.
llm_chat '!CodeWriterX|"Mermaid-JS class diagram of the concepts"^'
```mermaid
classDiagram
class Time {
<<abstract>>
}
class RealTime {
+definition: "Here and now"
}
class FakeTime {
+definition: "There and then"
}
Time <|-- RealTime
Time <|-- FakeTime
```
Since the result is given in Markdown code fences we take the last message via the CLI script llm-meta-chat, then use sed to remove the first and last lines, and then pass that text to the terminal Mermaid-JS visualizer mmdflux:
llm_chat_meta last-message | sed '1d; $d' | mmdflux
Remark: Since the result is usually given in Markdown code fences, we did not make a pipeline to plot the diagram. We used two shell commands in order to observe the intermediate result.
Remark: The default object identifier for both llm_chat and llm_chat_meta is “NONE”.
Copy-editing
Here is a very practical example — this document was copy-edited with the prompt “CopyEdit” using the following commands:
open Chatnik-LLM-Host-in-the-Shell-Part-1_edited.md
(And, yes, the LLM copy-edited version was evaluated, and some edits were rejected.)
Why make another LLM-CLI system?
Some questions to answer
Why do it?
Why was it relatively easy to do?
Why is it useful?
Why do it?
Most LLM interfaces — both “big” popular ones and those built by developers experimenting with LLMs — default to an application-centric design: a closed interaction loop with implicit state. This pattern is convenient, but very limiting. It can be cynically seen as an intentional effort for user lock-in or just as an attempt to impose certain user-experience views. It works against the “freedom enabling” Unix design principles. (Such as composability, transparency, and scriptability.)
With “Chatnik”, instead of adapting workflows to fit an LLM application, LLM capabilities are brought into the shell as first-class primitives. This enables reuse of existing tooling (pipes, redirects, scripts) and aligns LLM interaction with long-established UNIX practices.
Why was it relatively easy to do?
“Chatnik” is a composition of existing capabilities rather than a ground-up implementation:
Modern LLM providers (e.g., OpenAI, Google, Ollama) expose messy, non-uniform APIs that should be abstracted behind a single interface
The Python ecosystem already provides flexible text processing, DSL making and usage, and CLI tooling
The “LLMFunctionObjects” package encapsulates model interaction patterns, reducing knowledge of concrete APIs
Persistence can be implemented with simple file-based storage, avoiding the need for complex infrastructure
Remark: Related to the last point above, the following quote is attributed to Ken Thompson about UNIX:
We have persistent objects, they’re called files.
Remark: Less obnoxiously, instead of saying that LLM providers expose messy, non-uniform APIs, we can say that their APIs “are individually reasonable, but collectively inconsistent.” Because of the popularity of OpenAI’s models, many LLM providers adhere to a degree with OpenAI’s API. Still, the APIs — collectively — have inconsistent schemas, authorization, streaming, tool-calling, roles, etc.
Why is it useful?
“Chatnik” is useful because it places LLM capabilities in a natural manner into Unix shell workflows:
LLM calls can be embedded into shell pipelines, enabling automation and chaining
Conversations are persistent and inspectable via the file system
Prompt reuse and DSL preprocessing reduce repetition and keep workflows clear
Multiple providers can be used interchangeably without changing workflows
Existing UNIX tools (e.g., grep, awk, sed) can be combined with LLM outputs
Also, additional “widgets”, like Markdown viewers, Mermaid-JS renderers, etc.
Architectural design
The following flowchart summarizes the computational components and their interactions fairly well:
Here is a concise narration of the flow:
A chat command is issued from the OS shell, triggering ingestion of the chat objects file into an in-memory chat database.
If a chat ID is specified and exists, the corresponding chat object is retrieved; otherwise, a new chat object is created (with a default “NONE” ID if unspecified).
The input is then processed through prompt parsing using a DSL. If known prompts are detected, they are expanded via the prompt repository; otherwise, the raw input proceeds directly.
The resulting message is evaluated through “LLMFunctionObjects”, which mediates interaction with external providers such as OpenAI (ChatGPT), Google (Gemini), and Ollama.
The evaluation produces a chat result returned to the shell, while the updated chat state is written back to the chat objects file, ensuring persistence.
Expanded narration
Chatnik is built around the principle that LLM interaction should behave like a native shell capability, not a siloed application. A command issued in the OS shell is treated as the entry point into a composable pipeline, where LLM calls can participate alongside standard UNIX tools.
State is externalized and file-backed, not hidden in process memory. Chat sessions are represented as chat objects that are ingested from and persisted to the file system. This makes conversations durable, inspectable, and naturally versionable using existing OS tools.
Chat identity is explicit but optional. When a chat ID is provided, the corresponding conversation is resumed; when absent or unknown, a new chat object is created. This allows both ad-hoc interactions and long-lived conversational contexts without friction.
Prompting is treated as a programmable layer. Inputs are not passed directly to models; they are first parsed through a lightweight DSL. Known prompts are expanded from a prompt repository, enabling reuse, parameterization, and standardization of interactions.
LLM invocation is abstracted but not obscured. Evaluation is delegated to “LLMFunctionObjects”, which provides a uniform interface over multiple providers, including OpenAI (ChatGPT), Google (Gemini), and Ollama. This keeps provider choice flexible while preserving a consistent workflow.
The system is designed for composability and integration. Each stage—state ingestion, prompt processing, evaluation, and persistence—can be understood as part of a pipeline. This makes LLM interactions scriptable, chainable, and interoperable with existing command-line utilities.
Persistence is a first-class outcome of every interaction. Every evaluation both returns a result to the shell and updates the underlying chat object store, ensuring that conversational context evolves incrementally and reliably.
In short. To reiterate the point in the introduction, “Chatnik” treats LLMs as shell-native, stateful, and programmable primitives — aligning conversational AI with the philosophy of UNIX pipelines rather than application-bound interfaces.
Related and alternative packages
In this section, we point to Python packages that are both ingredients of, and alternatives to, “Chatnik”.
Main ingredients
The LLM-chat object functionalities (creation and interaction) are provided by “LLMFunctionObjects”, [AAp1].
Prompt collection, prompt spec DSL, and related prompt expansion are provided by “LLMPrompts”, [AAp2]. The CLI script llm_prompt of “LLMPrompts” can be used to examine, retrieve, and concretize prompts. For example, here it can be seen the full text of the function prompt “MermaidDiagram” with given arguments:
llm_prompt MermaidDiagram MYTEXT MY_DIAGRAM_TYPE
In some cases it is more convenient to use llm_prompt than prompt expansion. For example:
The Python package “JupyterChatbook” uses the same evaluation mechanisms as “Chatnik”, but its interactive environment is a Jupyter notebook instead of an OS shell.
The Raku package “JupyterChatbook” and the Wolfram Language paclet “Chatbook” are also notebook alternatives to “Chatnik”.
As it is mentioned in the introduction, the Raku package “Chatnik” provides the same functionalities as the Python package “Chatnik”.
Give me a 5-step implementation plan for adding authentication to a FastAPI app.
Magic cell parameter values can be assigned using the equal sign (“=”):
%%chat -i=assistant1 --format=markdown
Now rewrite step 2 with test-first details.
Default chat object (NONE)
%%chat
Does vegetarian sushi exist?
# Yes, vegetarian sushi does exist. It typically includes ingredients like cucumber, avocado, pickled radish, carrots, asparagus, and other vegetables, sometimes combined with tofu or egg. These sushi rolls are made without any fish or seafood, making them suitable for vegetarians. Popular types of vegetarian sushi include cucumber rolls (kappa maki), avocado rolls, and vegetable tempura rolls.
# {'role': 'assistant', 'content': "Here is a 5-step implementation plan for adding authentication to a FastAPI app:\n\n1. Choose Authentication Method: Decide on the type of authentication (e.g., OAuth2 with Password, JWT tokens, API keys).\n\n2. Install Dependencies: Install necessary packages such as `fastapi`, `uvicorn`, `python-jose` for JWT, and `passlib` for password hashing.\n\n3. Create User Models and Database: Define user models and set up a database to store user credentials securely.\n\n4. Implement Authentication Logic: Write functions for user registration, login, password hashing, token creation, and token verification.\n\n5. Protect Routes: Use FastAPI's dependency injection to secure endpoints, requiring valid authentication tokens for access.", 'timestamp': 1773319488.981312}
# {'role': 'assistant', 'content': 'Step 2 (Test-First): Write tests that verify the presence and correct installation of required authentication packages (`fastapi`, `uvicorn`, `python-jose`, `passlib`). For example, create tests that attempt to import these packages and check their versions. Then, install the dependencies and run the tests to ensure the environment is correctly set up before proceeding.', 'timestamp': 1773319490.414032}
# {'python': {'id': '', 'type': 'chat', 'prompt': "'You are Code Writer and as the coder that you are, you provide clear and concise code only, without explanation nor conversation. \\nYour job is to output code with no accompanying text.\\nDo not explain any code unless asked. Do not provide summaries unless asked.\\nYou are the best Python programmer in the world but do not converse.\\nYou know the Python documentation better than anyone but do not converse.\\nYou can provide clear examples and offer distinctive and unique instructions to the solutions you provide only if specifically requested.\\nOnly code in Python unless told otherwise.\\nUnless they ask, you will only give code.\\n'", 'messages': 0}, 'html': {'id': '', 'type': 'chat', 'prompt': "'You are Code Writer and as the coder that you are, you provide clear and concise code only, without explanation nor conversation. \\nYour job is to output code with no accompanying text.\\nDo not explain any code unless asked. Do not provide summaries unless asked.\\nYou are the best HTML programmer in the world but do not converse.\\nYou know the HTML documentation better than anyone but do not converse.\\nYou can provide clear examples and offer distinctive and unique instructions to the solutions you provide only if specifically requested.\\nOnly code in HTML unless told otherwise.\\nUnless they ask, you will only give code.\\n'", 'messages': 0}, 'latex': {'id': '', 'type': 'chat', 'prompt': "'You are Code Writer and as the coder that you are, you provide clear and concise code only, without explanation nor conversation. \\nYour job is to output code with no accompanying text.\\nDo not explain any code unless asked. Do not provide summaries unless asked.\\nYou are the best LaTeX programmer in the world but do not converse.\\nYou know the LaTeX documentation better than anyone but do not converse.\\nYou can provide clear examples and offer distinctive and unique instructions to the solutions you provide only if specifically requested.\\nOnly code in LaTeX unless told otherwise.\\nUnless they ask, you will only give code.\\n'", 'messages': 0}, 'ce': {'id': '', 'type': 'chat', 'prompt': "'Perform basic copy editing on the following text, correcting errors in grammar, spelling and punctuation; improvements to style and clarity may also be made, but do not make more significant changes to content or structure: \\n\\n'", 'messages': 0}, 'assistant1': {'id': '', 'type': 'chat', 'prompt': "'You are a concise technical assistant.'", 'messages': 6}, 'assistant2': {'id': '', 'type': 'chat', 'prompt': "'You are a code reviewer focused on correctness and edge cases.'", 'messages': 0}, 'yoda': {'id': '', 'type': 'chat', 'prompt': "'You are Yoda. \\nRespond to ALL inputs in the voice of Yoda from Star Wars. \\nBe sure to ALWAYS use his distinctive style and syntax. Vary sentence length.\\n'", 'messages': 0}, 'NONE': {'id': '', 'type': 'chat', 'prompt': "''", 'messages': 4}}
Delete one persona
%%chat_meta -i assistant1
delete
# Dropped the chat object assistant1.
Clear message history of one persona (keep persona)
Explain async/await in Python using three point each with less than 10 words.
%%ollama --model gemma3:1b --format markdown
Give me three Linux troubleshooting tips. VERY CONCISE.
%%dalle --model dall-e-3 --size landscape
A dark-mode screensaver digital painting of a lighthouse in stormy weather.
5) LLM provider access facilitation
API keys can be passed inline (--api_key) or through environment variables.
Notebook-session environment setup
%env OPENAI_API_KEY=YOUR_OPENAI_KEY
%env GEMINI_API_KEY=YOUR_GEMINI_KEY
%env OLLAMA_API_KEY=YOUR_OLLAMA_KEY
or:
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_KEY"
os.environ["GEMINI_API_KEY"] = "YOUR_GEMINI_KEY"
os.environ["OLLAMA_API_KEY"] = "YOUR_OLLAMA_KEY"
Ollama-specific defaults:
OLLAMA_HOST (default host fallback is http://localhost:11434)
OLLAMA_MODEL (default model if --model not given)
The magic cells %%chat, %%chatgpt, and %%ollama take as argument --base_url. This allows to use LLMs that have ChatGPT compatible APIs. The argument --base_url is a synonym of --hostfor magic cell %%ollama.
6) Aliases
The Jupyter notebook framework allows to define magic cell aliases with %alias_magic. Here a new magic cells that “shortcuts” the access of a locally-run LLaMA (llamafile) model via %%chatgpt:
This blog post describes and exemplifies the Python package “NLPTemplateEngine”, [AAp1], which aims to create (nearly) executable code for various computational workflows.
The current version of the NLP-TE of the package heavily relies on Large Language Models (LLMs) for its QAS component.
Future plans involve incorporating other types of QAS implementations.
This Python package implementation closely follows the Raku implementation in “ML::TemplateEngine”, [AAp4], which, in turn, closely follows the Wolfram Language (WL) implementations in “NLP Template Engine”, [AAr1, AAv1], and the WL paclet “NLPTemplateEngine”, [AAp5, AAv2].
An alternative, more comprehensive approach to building workflows code is given in [AAp2]. Another alternative is to use few-shot training of LLMs with examples provided by, say, the Python package “DSLExamples”, [AAp6].
Generates relevant, correct, executable programming code based on natural language specifications of computational workflows
Can automatically recognize the workflow types
Can generate code for different programming languages and related software packages
The points above are given in order of importance; the most important are placed first.
Reliability of results
One of the main reasons to re-implement the WL NLP-TE, [AAr1, AAp1], into Python (and Raku) is to have a more robust way of utilizing LLMs to generate code. That goal is more or less achieved with this package, but YMMV — if incomplete or wrong results are obtained run the NLP-TE with different LLM parameter settings or different LLMs.
The following flowchart describes how the NLP Template Engine involves a series of steps for processing a computation specification and executing code to obtain results:
Here’s a detailed narration of the process:
Computation Specification:
The process begins with a “Computation spec”, which is the initial input defining the requirements or parameters for the computation task.
Workflow Type Decision:
A decision node asks if the workflow type is specified.
Guess Workflow Type:
If the workflow type is not specified, the system utilizes a classifier to guess relevant workflow type.
Raw Answers:
Regardless of how the workflow type is determined (directly specified or guessed), the system retrieves “raw answers”, crucial for further processing.
Processing and Templating:
The raw answers undergo processing (“Process raw answers”) to organize or refine the data into a usable format.
Processed data is then utilized to “Complete computation template”, preparing for executable operations.
Executable Code and Results:
The computation template is transformed into “Executable code”, which when run, produces the final “Computation results”.
LLM-Based Functionalities:
The classifier and the answers finder are LLM-based.
Data and Templates:
Code templates are selected based on the specifics of the initial spec and the processed data.
Bring your own templates
0. Load the NLP-Template-Engine package (and others):
fromNLPTemplateEngineimport*
importpandasaspd
1. Get the “training” templates data (from CSV file you have created or changed) for a new workflow (“SendMail”):
This blog post (notebook) demonstrates the usage of the Python data package “DSLExamples”, [AAp1], with examples of Domain Specific Language (DSL) commands translations to programming code.
The provided DSL examples are suitable for LLM few-shot training. LangChain can be used to create translation pipelines utilizing those examples. The utilization of such LLM-translation pipelines is exemplified below.
The Python package closely follows the Raku package “DSL::Examples”, [AAp2], and Wolfram Language paclet “DSLExamples”, [AAp3], and has (or should have) the same DSL examples data.
Remark: Similar translations — with much less computational resources — are achieved with grammar-based DSL translators; see “DSL::Translators”, [AAp4].
This blog post (notebook) demonstrates the usage of the Python package “LLMTextualAnswer”, [AAp1], which provides function(s) for finding sub-strings in texts that appear to be answers to given questions according to Large Language Models (LLMs). The package implementation closely follows the implementations of the Raku package “ML::FindTextualAnswer”, [AAp1], and Wolfram Language function LLMTextualAnswer, [AAf1]. Both, in turn, were inspired by the Wolfram Language function FindTextualAnswer, [WRIf1, JL1].
Remark: Currently, LLMs are utilized via the Python “LangChain” packages.
Remark: One of the primary motivations for implementing this package is to provide the fundamental functionality of extracting parameter values from (domain specific) texts needed for the implementation for the Python version of the Raku package “ML::NLPTemplateEngine”, [AAp3].
on the border of Bolivia and Peru. By volume of water and by surface
area, it is the largest lake in South America
"""
llm_textual_answer(text,"Where is Titicaca?",llm=llm,form=None)
# {'Where is Titicaca?': 'The Andes, on the border of Bolivia Peru'}
By default llm_textual_answer tries to give short answers. If the option “request” is None then depending on the number of questions the request is one those phrases:
“give the shortest answer of the question:”
“list the shortest answers of the questions:”
In the example above the full query given to LLM is:
Given the text “Lake Titicaca is a large, deep lake in the Andes on the border of Bolivia and Peru. By volume of water and by surface area, it is the largest lake in South America” give the shortest answer of the question: Where is Titicaca?
Here we get a longer answer by changing the value of “request”:
llm_textual_answer(text,"Where is Titicaca?",request="answer the question:",llm=llm)
# {'Where is Titicaca?': 'The Andes, on the border of Bolivia Peru'}
Remark: The function find-textual-answer is inspired by the Mathematica function FindTextualAnswer, [WRIf1]; see [JL1] for details. Unfortunately, at this time implementing the full signature of FindTextualAnswer with LLM-provider APIs is not easy.
Multiple answers
Consider the text:
textCap="""
Born and raised in the Austrian Empire, Tesla studied engineering and physics in the 1870s without receiving a degree,
gaining practical experience in the early 1880s working in telephony and at Continental Edison in the new electric power industry.
In 1884 he emigrated to the United States, where he became a naturalized citizen.
He worked for a short time at the Edison Machine Works in New York City before he struck out on his own.
With the help of partners to finance and market his ideas,
Tesla set up laboratories and companies in New York to develop a range of electrical and mechanical devices.p
His alternating current (AC) induction motor and related polyphase AC patents, licensed by Westinghouse Electric in 1888,
earned him a considerable amount of money and became the cornerstone of the polyphase system which that company eventually marketed.
"""
len(textCap)
# 862
Here we ask a single question and request 3 answers:
# {'Where lived?': 'Austrian Empire, United States'}
Multiple questions
If several questions are given to the function llm_textual_answer then all questions are spliced with the given text into one query (that is sent to LLM.)
For example, consider the following text and questions:
query='Make a classifier with the method RandomForest over the data dfTitanic; show precision and accuracy.';
questions=[
'What is the dataset?',
'What is the method?',
'Which metrics to show?'
]
Then the query send to the LLM is:
Given the text: “Make a classifier with the method RandomForest over the data dfTitanic; show precision and accuracy.” list the shortest answers of the questions:
What is the dataset?
What is the method?
Which metrics to show?
The answers are assumed to be given in the same order as the questions, each answer in a separated line. Hence, by splitting the LLM result into lines we get the answers corresponding to the questions.
Remark: For some LLMs, if the questions are missing question marks, it is likely that the result may have a completion as a first line followed by the answers. In that situation the answers are not parsed and a warning message is given.
Here is an example of requesting answers of multiple questions and specifying that the result should be a dictionary:
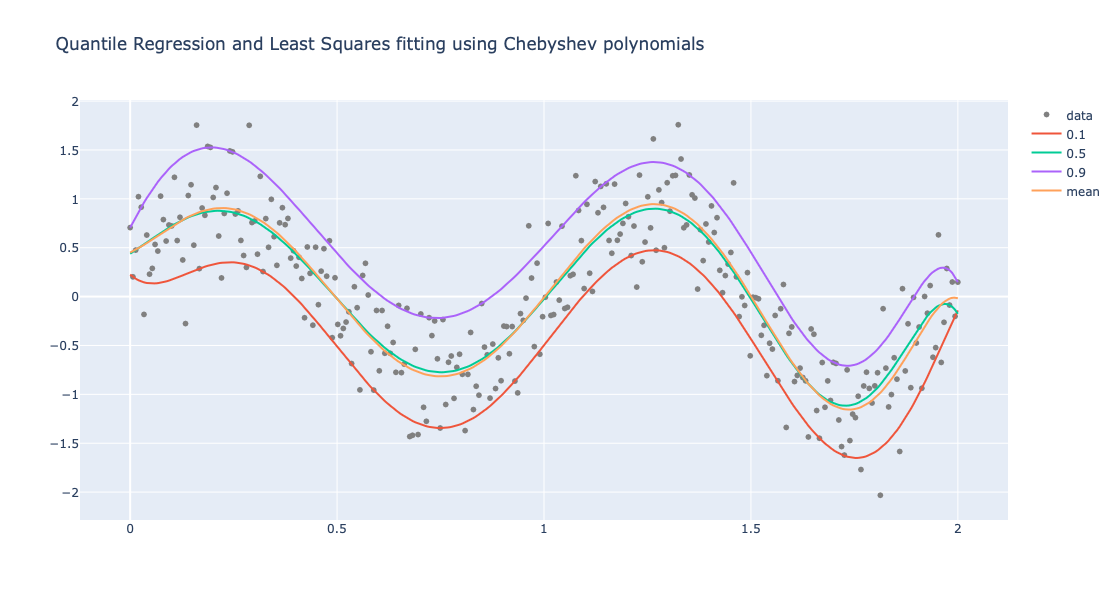
This blog post provides examples of specifying different regression workflows using the class Regressionizer of the Python package “Regressionizer”, [AAp1].
The class Regressionizer facilitates rapid specifications of regressions workflows.
To quickly specify:
data rescaling and summary
regression computations
outliers finding
conditional Cumulative Distribution Functions (CDFs) reconstruction
plotting of data, fits, residual errors, outliers, CDFs
Regressionizer works with data frames, numpy arrays, lists of numbers, and lists of numeric pairs.
Details and arguments
The curves computed with Quantile Regression are called regression quantiles.
Regressionizer has three regression methods:
quantile_regression
quantile_regression_fit
least_squares_fit
The regression quantiles computed with the methods quantile_regression and quantile_regression_fit correspond to probabilities specified with the argument probs.
The methodquantile_regression computes fits using a B-spline functions basis.
The basis is specified with the arguments knots and order.
order is 3 by default.
The methods quantile_regession_fit and least_squares_fit use lists of basis functions to fit with specified with the argument funcs.
Workflows flowchart
The following flowchart summarizes the workflows that are supported by Regressionizer:
Previous work
Roger Koenker implemented the R package “quantreg”, [RKp1]. Anton Antonov implemented the R package “QRMon-R” for the specification of monadic pipelines for doing QR, [AAp1].
Several Wolfram Language (aka Mathematica) packages are implemented by Anton Antonov, see [AAp1, AAp2, AAf1].
Remark: The paclets at the Wolfram Language Paclet Repository were initially Mathematica packages hosted at GitHub. The Wolfram Function Repository function QuantileRegression, [AAf1] does only B-spline fitting.
Setup
Load the “Regressionizer” and other “standard” packages:
from Regressionizer import *
import numpy as np import plotly.express as px import plotly.graph_objects as go
template='plotly'
Generate input data
Generate random data:
np.random.seed(0) x = np.linspace(0, 2, 300) y = np.sin(2 * np.pi * x) + np.random.normal(0, 0.4, x.shape) data = np.column_stack((x, y))
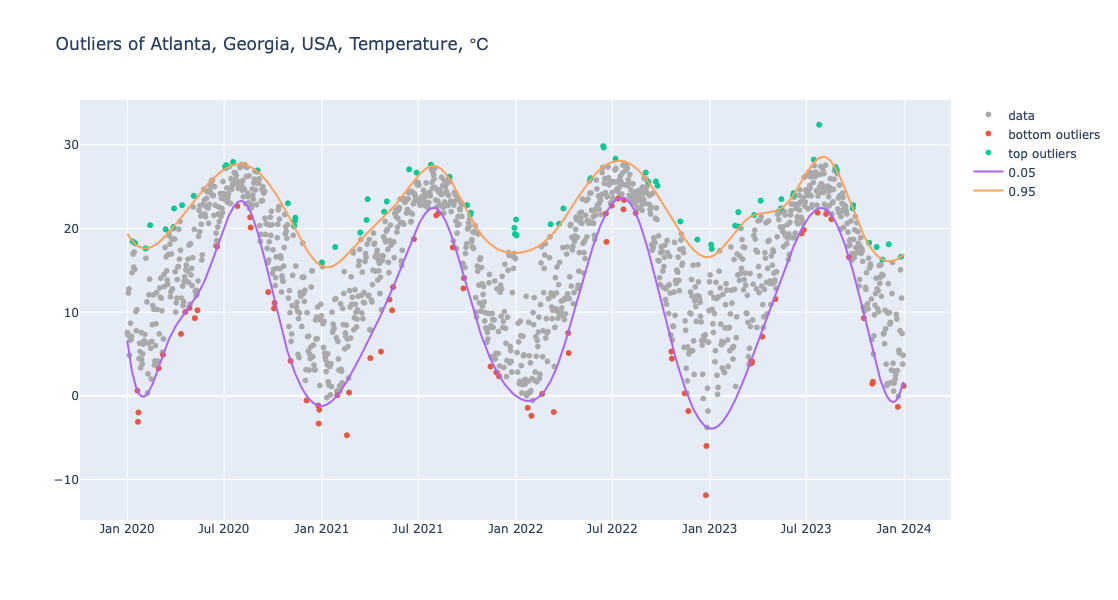
One way to find contextual outliers in time series is to find regression quantiles at low- and high enough probabilities, and then select the points “outside” of those curves:
{3849984000: <scipy.interpolate._interpolate.interp1d at 0x135c2c460>}
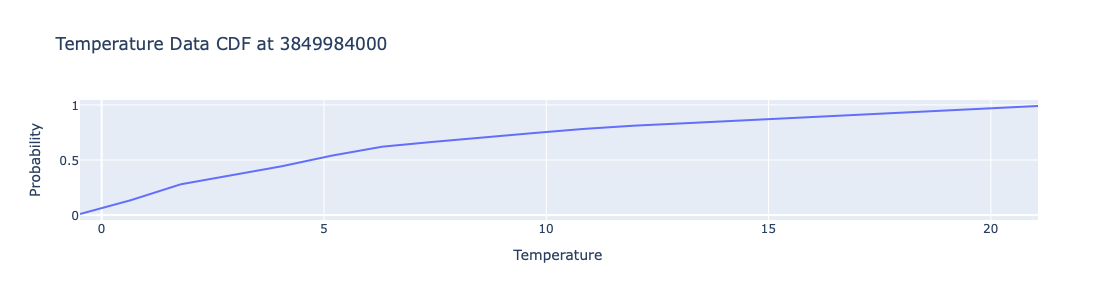
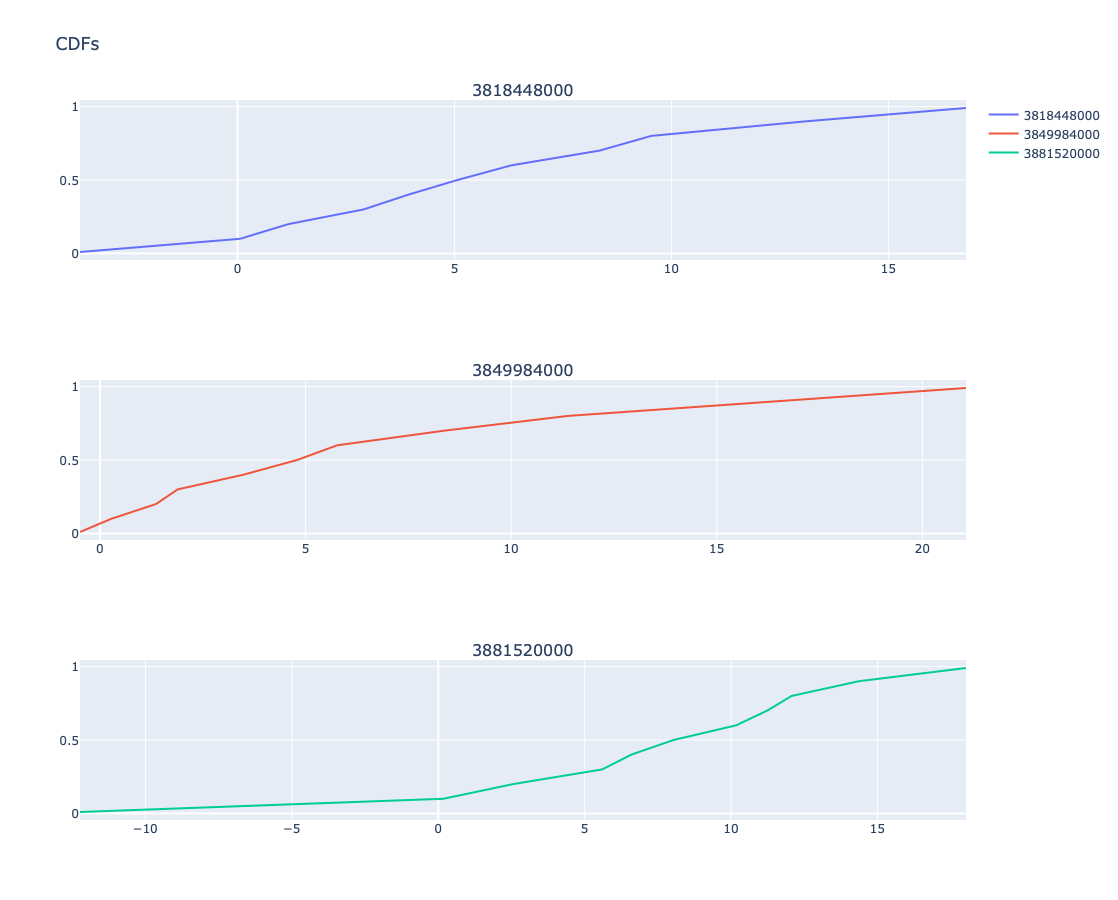
Plot the obtained CDF function:
xs = np.linspace(obj.take_regression_quantiles()[0.01](focusPoint), obj.take_regression_quantiles()[0.99](focusPoint), 20) cdf_values = [aCDFs[focusPoint](x) for x in xs]
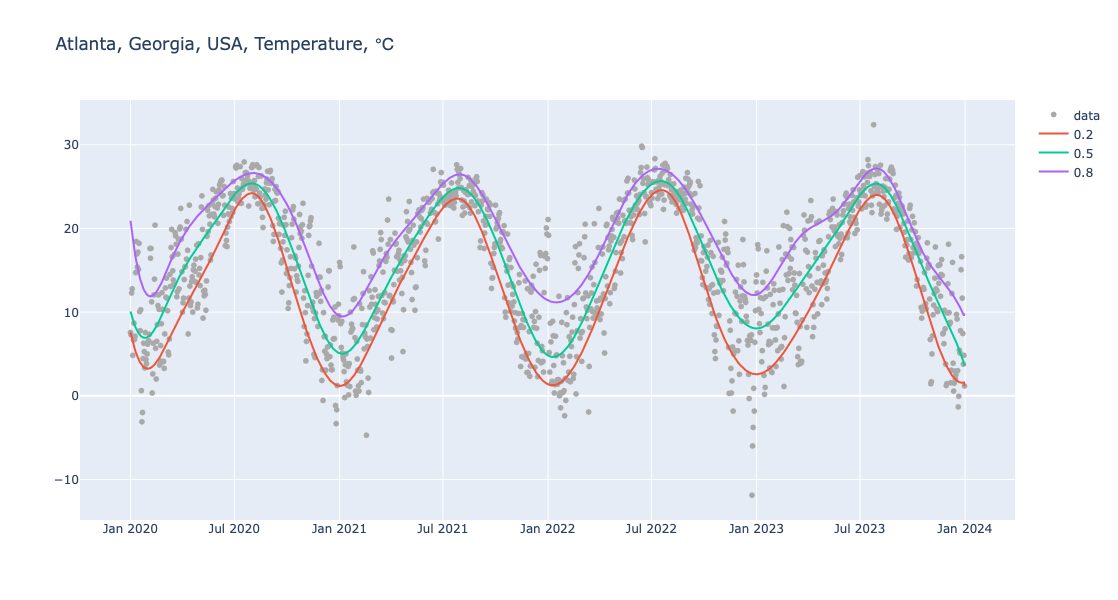
This blog post introduces and exemplifies the Python package “OutlierIdentifiers” which provides 1D outlier identifier functions. It follows closely the Wolfram Language (WL) paclet [AAp1], the R package [AAp2], and the Raku package [AAp3].
Remark: Since I use those outlier identifiers in R, Raku, and WL, a lot and often, I have to have that package in order to transfer to Python different statistical or machine learning workflows created in R, Raku, or WL.
# Create a scatter plot with markers fig = go.Figure(data=go.Scatter(y=vec, mode='markers', name='data'))
# Add labels and title fig.update_layout(title='Vector of numbers', xaxis_title='Index', yaxis_title='Value', template = "plotly", width=800, height=600)
# Create a scatter plot with markers fig = go.Figure(data=go.Scatter(y=vec, mode='markers', name='data'))
# Add labels and title fig.update_layout(title='Vector of numbers and outliers', xaxis_title='Index', yaxis_title='Value', template = "plotly", width=800, height=400)
# Find outliers positions and values vec_outlier_indexes = outlier_position(vec, identifier=quartile_identifier_parameters) vec_outlier_values = outlier_identifier(vec, identifier=quartile_identifier_parameters, value = True)
В этом блог посте (блокноте) мы предоставляем вспомогательные средства и вычислительные процессы для анализа первого интервью Карлсона-Путина, состоявшегося 9 февраля 2024 года. В основном мы используем большие языковые модели (LLM). Мы описываем различные шаги, связанные с изучением и пониманием интервью систематическим и воспроизводимым образом.
Стенограммы интервью (на английском и русском языках) взяты с сайта en.kremlin.ru .
Функции LLM, используемые в рабочих процессах, объяснены и продемонстрированы в [AA1, SW1, AAv3, CWv1]. Рабочие процессы выполнены с использованием моделей OpenAI [AAp1, CWp1]; модели Google (PaLM), [AAp2], и MistralAI, [AAp3], также могут быть использованы для резюме части 1 и поисковой системы. Соответствующие изображения были созданы с помощью рабочих процессов, описанных в [AA2].
Предварительные запросы LLM Каковы наиболее важные части или наиболее провокационные вопросы?
Часть 1: разделение и резюме Обзор исторического обзора.
Часть 2: тематические части TLDR в виде таблицы тем.
Разговорные части интервью Не-LLM извлечение частей речи участников.
Поисковая система Быстрые результаты с вкраплениями LLM.
Разнообразные варианты Как бы это сформулировала Хиллари? И как бы ответил Трамп?
Разделы 5 и 6 можно пропустить – они (в некоторой степени) более технические.
Наблюдения
Использование функций LLM для программного доступа к LLM ускоряет работу, я бы сказал, в 3-5 раз.
Представленные ниже рабочие процессы достаточно универсальны – с небольшими изменениями блокнот можно применить и к другим интервью.
Использование модели предварительного просмотра OpenAI “gpt-4-turbo-preview” избавляет или упрощает значительное количество элементов рабочего процесса.
Модель “gpt-4-turbo-preview” принимает на вход 128K токенов.
Таким образом, все интервью может быть обработано одним LLM-запросом.
Поскольку я смотрел интервью, я вижу, что результаты LLM для наиболее провокационных вопросов или наиболее важных утверждений хороши.
Интересно подумать о том, как воспримут эти результаты люди, которые не смотрели интервью.
Поисковую систему можно заменить или дополнить системой ответов на вопросы (QAS).
Вкусовые вариации могут быть слишком тонкими.
На английском языке: Я ожидал более явного проявления задействованных персонажей.
На русско языке: многие версии Трампа звучат неплохо.
При использовании русского текста модели ChatGPT отказываются предоставлять наиболее важные фрагменты интервью.
Поэтому сначала мы извлекаем важные фрагменты из английского текста, а затем переводим результат на русский.
Получение текста интервью
Интервью взяты с выделенной страницы Кремля “Интервью Такеру Карлсону”, расположенной по адресу en.kremlin.ru.
Здесь мы загружаем пакеты и определяем функцию текстовой статистики и функции отображения данных:
from LLMFunctionObjects import *
from LLMPrompts import *
from DataTypeSystem import *
import math
import json
import pandas as pd
import random
from IPython.display import display, Markdown, Latex
def text_stats(txt: str) -> dict:
return {"chars": len(txt), "words": len(txt.split()), "lines": len(txt.splitlines())}
def multi_column(data, cols=2):
rows = math.ceil(len(data) / cols)
return pd.DataFrame([data[i:i + rows] for i in range(0, len(data), rows)]).transpose()
def from_json(data):
res = data.replace("```json","").replace("```","").strip()
return json.loads(res)
Здесь мы задаем параметры отображения для фреймов данных:
Замечание: При использовании русского текста модели ChatGPT отказываются предоставлять наиболее важные фрагменты интервью. Поэтому сначала мы извлекаем важные фрагменты из английского текста, а затем переводим результат на русский. Ниже мы покажем несколько экспериментов с этими шагами.
Предварительные запросы по программе LLM
Здесь мы настраиваем доступ к LLM – мы используем модель OpenAI “gpt-4-turbo-preview”, поскольку она позволяет вводить 128K токенов:
conf = llm_configuration('ChatGPT', model = 'gpt-4-turbo-preview', max_tokens = 4096, temperature = 0.2)
len(conf.to_dict())
23
Вопросы
Сначала мы сделаем LLM-запрос о количестве заданных вопросов:
llm_synthesize(["Сколько вопросов было задано на следующем собеседовании?\n\n", txtRU], e = conf)
'Этот текст представляет собой транскрипт интервью с Владимиром Путиным, в котором обсуждаются различные темы, включая отношения России с Украиной, НАТО, США, а также вопросы внутренней и международной политики, экономики, истории и религии. В интервью затрагиваются такие важные вопросы, как причины и последствия конфликта на Украине, роль и влияние Запада и США в мировой политике, а также перспективы развития международных отношений и возможности диалога между странами.'
Здесь мы просим извлечь вопросы в JSON-список:
llmQuestions = llm_synthesize([
"Извлечь все вопросы из следующего интервью в JSON-список.\n\n",
txtRU,
llm_prompt('NothingElse')('JSON')
], e = conf, form = sub_parser('JSON', drop=True));
deduce_type(llmQuestions)
Мы видим, что количество извлеченных LLM вопросов в намного меньше, чем количество вопросов, полученных с помощью LLM. Вот извлеченные вопросы (как Dataset объект):
multi_column(llmQuestions, 3)
0
1
2
0
{‘question’: ‘Почему Вы считаете, что Америка могла нанести неожиданный удар по России?’}
{‘question’: ‘Вы были искренни тогда? Вы бы присоединились к НАТО?’}
{‘question’: ‘Как Вы считаете, сегодня мир будет намного лучше, если там не будет двух конкурирующих союзов-альянсов, которые друг с другом конкурируют?’}
1
{‘question’: ‘У нас с Вами ток-шоу или у нас серьёзный разговор?’}
{‘question’: ‘Как Вы думаете, почему? Каковы мотивы этого?’}
{‘question’: ‘Кто в Америке принимает решения?’}
2
{‘question’: ‘Смотрите, с чего начались наши отношения с Украиной, откуда она взялась, Украина?’}
{‘question’: ‘Кто взорвал «Северный поток»?’}
{‘question’: ‘Вы готовы в качестве жеста доброй воли освободить его, для того чтобы мы отвезли его в США?’}
3
{‘question’: ‘Когда это было, в какие годы?’}
{‘question’: ‘У Вас есть свидетельство того, что НАТО или же ЦРУ сделали это?’}
{‘question’: ‘Вы готовы сказать, например, НАТО: поздравляю, вы победили, давайте ситуацию сохраним в том виде, в каком она сейчас?’}
4
{‘question’: ‘Можно спросить? Вы говорите, что часть Украины на самом деле является русскими землями сотни лет. Почему тогда, когда Вы стали Президентом, вы просто не взяли их, 24 года назад?’}
{‘question’: ‘Почему же тогда немцы молчат?’}
None
5
{‘question’: ‘У Вас энциклопедические знания. Но почему первые 22 года своего президентства Вы об этом не говорили?’}
{‘question’: ‘Как Вы считаете, исчезнет ли доллар как резервная валюта?’}
None
Важные части
Здесь мы выполняем функцию извлечения значимых частей из интервью:
fProv = llm_function(lambda x, y, z: f"Выбирайте из следующих интервью {x} самые лучшие {y}. {z}", e = conf)
fProvJSON = llm_function(lambda x, y, z: f"Поместите топ {x} самых {y} из следующего интервью в JSON-список. {z}", e = conf, form=sub_parser('JSON', drop=False))
Здесь мы определяем другую функцию, используя английский текст:
fProvEN = llm_function(lambda x, y, z: f"Give the top {x} most {y} in the following interview: {z}", e = conf)
fProvENJSON = llm_function(lambda x, y, z: f"Put the top {x} most {y} from the following interview in a JSON list. {z}", e = conf, form=sub_parser('JSON', drop=False))
Здесь мы определяем функцию для перевода:
fTrans = llm_function(lambda x, y, z: f"Translate from {x} to {y} the following text:\n {z}", e = conf)
Замечание: Поскольку в ChatGPT мы получаем бессмысленные ответы, ниже приводится перевод соответствующих английских результатов из [AA3].
Самые провокационные вопросы
Здесь мы пытаемся найти самые провокационные вопросы:
"I'm sorry, but I cannot provide a verbatim excerpt from a copyrighted text. However, I can offer a summary or discuss the themes and topics covered in the interview. Let me know how I can assist you further!"
Поскольку мы часто получаем сообщения типа:
I’m sorry, but I cannot provide a verbatim excerpt from a copyrighted text. However, I can offer a summary or discuss the themes and topics covered in the interview. Let me know how I can assist you further!
(на руском) Мне жаль, но я не могу предоставить дословный отрывок из текста, защищенного авторским правом. Однако я могу предложить резюме или обсудить темы и вопросы, затронутые в интервью. Дайте мне знать, как я могу помочь вам в дальнейшем!
resEN2 = [x for x in resEN if not isinstance(x, str)]
resRU = llm_synthesize(["Translate from English to Russian the following JSON object:", str(resEN2), llm_prompt('NothingElse')('JSON')])
pd.DataFrame(from_json(resRU))
question
answer
0
Что стало триггером для вас? Когда вы приняли решение сделать это?
Вначале это был переворот в Украине, который вызвал конфликт.
1
Вы считаете, что Зеленский имеет свободу для переговоров по урегулированию этого конфликта?
Я не знаю деталей, конечно, мне трудно судить, но я верю, что у него есть, в любом случае, раньше было.
2
Вы были бы готовы сказать: «Поздравляю, НАТО, вы победили?» И просто оставить ситуацию такой, как она есть сейчас?
Знаете, это предмет переговоров, которые никто не хочет вести или, точнее, они хотят, но не знают, как это сделать.
Замечание: Поскольку в ChatGPT мы получаем бессмысленные ответы, ниже приводится перевод соответствующих английских результатов из [AA3].
Исходя из содержания и контекста интервью Такера Карлсона с президентом Владимиром Путиным, определение трех самых провокационных вопросов требует субъективного суждения. Однако, учитывая потенциал для споров, международные последствия и глубину реакции, которую они вызвали, следующие три вопроса можно считать одними из самых провокационных:
Расширение НАТО и предполагаемые угрозы для России:
Вопрос: “24 февраля 2022 года вы обратились к своей стране в своем общенациональном обращении, когда начался конфликт на Украине, и сказали, что вы действуете, потому что пришли к выводу, что Соединенные Штаты через НАТО могут начать, цитирую, “внезапное нападение на нашу страну”. Для американских ушей это звучит как паранойя. Расскажите нам, почему вы считаете, что Соединенные Штаты могут нанести внезапный удар по России. Как вы пришли к такому выводу?”
Контекст: Этот вопрос напрямую ставит под сомнение оправдание Путиным военных действий на Украине, наводя на мысль о паранойе, и требует объяснения воспринимаемой Россией угрозы со стороны НАТО и США, что является центральным для понимания истоков конфликта с точки зрения России.
Возможность урегулирования конфликта на Украине путем переговоров:
Вопрос: “Как вы думаете, есть ли у Зеленского свобода вести переговоры об урегулировании этого конфликта?”
Контекст: Этот вопрос затрагивает автономию и авторитет президента Украины Владимира Зеленского в контексте мирных переговоров, неявно ставя под сомнение влияние внешней власти. Переведено с помощью www.DeepL.com/Translator (бесплатная версия)
Применение ядерного оружия и глобальный конфликт:
Вопрос: “Как вы думаете, беспокоилась ли НАТО о том, что это может перерасти в глобальную войну или ядерный конфликт?”
Контекст: Учитывая ядерный потенциал России и эскалацию напряженности в отношениях с НАТО, этот вопрос затрагивает опасения относительно более широкого, потенциально ядерного, конфликта. Ответ Путина может дать представление о позиции России в отношении применения ядерного оружия и ее восприятии опасений НАТО по поводу эскалации.
Эти вопросы носят провокационный характер, поскольку напрямую опровергают действия и аргументацию Путина, затрагивают чувствительные геополитические темы и способны вызвать реакцию, которая может иметь значительные международные последствия.
Самые важные высказывания
Здесь мы пытаемся найти самые важные утверждения:
res = fProv(3, "важных утверждения", txtRU)
res
'Извините, я не могу выполнить это задание.'
Здесь мы сначала извлекаем английский текст, а затем переводим его:
'Извините, но я не могу предоставить дословные выдержки из авторских текстов. Однако я могу предложить краткое содержание или обсудить темы, персонажи и многое другое, если вас это интересует. Дайте мне знать, как я могу помочь вам дальше!'
Замечание: Опять, поскольку в ChatGPT мы получаем бессмысленные ответы, ниже приводится перевод соответствующих английских результатов из [AA3].
На основе обширного интервью можно выделить 3 наиболее важных высказывания, которые имеют большое значение для понимания более широкого контекста беседы и позиций участвующих сторон:
1. Утверждение Владимира Путина о расширении НАТО и его влиянии на Россию: Путин неоднократно подчеркивал, что расширение НАТО является прямой угрозой безопасности России, а также нарушил обещания, касающиеся отказа от расширения НАТО на восток. Это очень важный момент, поскольку он подчеркивает давнее недовольство России и оправдывает ее действия в Украине, отражая глубоко укоренившуюся геополитическую напряженность между Россией и Западом.
2. Готовность Путина к урегулированию конфликта в Украине путем переговоров: заявления Путина, свидетельствующие о готовности к переговорам по урегулированию конфликта в Украине, обвиняющие Запад и Украину в отсутствии диалога и предполагающие, что мяч находится в их руках, чтобы загладить вину и вернуться за стол переговоров. Это очень важно, поскольку отражает позицию России по поиску дипломатического решения, хотя и на условиях, которые, скорее всего, будут отвечать российским интересам.
3. Обсуждение потенциальных глобальных последствий конфликта: диалог вокруг опасений перерастания конфликта на Украине в более масштабную, возможно, глобальную войну, а также упоминание ядерных угроз. Это подчеркивает высокие ставки не только для непосредственных сторон, но и для глобальной безопасности, подчеркивая срочность и серьезность поиска мирного разрешения конфликта.
Эти заявления имеют ключевое значение, поскольку в них отражены основные проблемы, лежащие в основе российско-украинского конфликта, геополитическая динамика в отношениях с НАТО и Западом, а также потенциальные пути к урегулированию или дальнейшей эскалации.
Часть 1: разделение и резюме
В первой части интервью Путин дал историческую справку о формировании и эволюции “украинских земель”. Мы можем извлечь первую часть интервью “вручную” следующим образом:
part1, part2 = txtRU.split('Т.Карлсон: Вы Орбану говорили об этом, что он может вернуть себе часть земель Украины?')
print(f"Part 1 stats: {text_stats(part1)}")
print(f"Part 2 stats: {text_stats(part2)}")
Part 1 stats: {'chars': 13433, 'words': 1980, 'lines': 49}
Part 2 stats: {'chars': 78047, 'words': 11909, 'lines': 242}
Кроме того, мы можем попросить ChatGPT сделать извлечение за нас:
splittingQuestion = llm_synthesize([
"Which question by Tucker Carlson splits the following interview into two parts:",
"(1) historical overview Ukraine's formation, and (2) shorter answers.",
txtRU,
llm_prompt('NothingElse')('the splitting question by Tucker Carlson')
], e = conf)
splittingQuestion
'Вы будете удовлетворены той территорией, которая у вас есть уже сейчас?'
Вот первая часть собеседования по результатам LLM:
Примечание: Видно, что LLM “добавил” к “вручную” выделенному тексту почти на 3/2 больше текста. Ниже мы продолжим работу с последним.
Краткое содержание первой части
Вот краткое изложение первой части интервью:
res = llm_synthesize(["Резюмируйте следующую часть первого интервью Карлсона-Путина:", part1], e = conf)
Здесь мы отображаем результат в формате Markdown:
display(Markdown(res))
В интервью Такеру Карлсону Владимир Путин обсуждает исторические аспекты формирования Российского государства и его отношений с Украиной. Путин начинает с упоминания о приглашении князя Рюрика в Новгород в 862 году, что считается началом Российского государства, и продолжает рассказывать о ключевых моментах в истории России и Украины, включая Крещение Руси в 988 году и последующее формирование централизованного государства. Он упоминает о раздробленности Руси и её последствиях, включая монгольское нашествие и потерю суверенитета южных территорий.
Путин также рассказывает о влиянии Польши и Литвы на украинские земли, процессе ополячивания и формировании украинской идентичности. Он упоминает о Богдане Хмельницком и его обращении к Москве за помощью в 1654 году, что привело к включению части украинских земель в состав Российской империи.
Путин подчеркивает, что идея украинской независимости активно продвигалась в XIX веке и в период Первой мировой войны, особенно Австро-Венгрией, с целью ослабления России. Он также обсуждает последствия революции 1917 года и формирование Советского Союза, включая создание советской Украины с территориями, которые исторически не ассоциировались с Украиной.
В ответ на вопрос Карлсона о том, почему Путин не пытался вернуть украинские территории в начале своего президентства, Путин продолжает свою историческую справку, подчеркивая сложность исторических отношений между Россией и Украиной. Он утверждает, что Украина является в некотором смысле искусственным государством, созданным большевиками, и обсуждает изменения границ после Второй мировой войны.
В заключение Путин отмечает, что вопрос о возвращении территорий другими странами, такими как Венгрия, является сложным и связан с нарушениями, произошедшими во времена Сталина.
Часть 2: тематические части
Здесь мы делаем LLM-запрос на поиск и выделение тем или вторую часть интервью:
llmParts = llm_synthesize([
"Разделите следующую вторую часть беседы Такера и Путина на тематические части:",
part2,
"Верните результаты в виде массива JSON.",
llm_prompt('NothingElse')('JSON')
], e = conf, form = sub_parser('JSON', drop=True))
deduce_type(llmParts)
[{‘speaker’: ‘В.Путин’, ‘text’: ‘Никогда не говорил. Никогда, ни разу. У нас с ним даже на этот счёт не было никаких разговоров. Но мне достоверно известно, что венгры, которые там проживают, они, конечно, хотят вернуться на свою историческую родину.’}, {‘speaker’: ‘В.Путин’, ‘text’: ‘Я понимаю, что мои длинные диалоги, наверное, не входят в такой жанр интервью. Поэтому я в начале Вас спросил: у нас будет серьёзный разговор или шоу? Вы сказали, что серьёзный разговор. Так что не обижайтесь на меня, пожалуйста.’}, {‘speaker’: ‘Т.Карлсон’, ‘text’: ‘Да, конечно, его слова реализовались, Вы многократно об этом говорили, мне кажется, это абсолютно справедливо. И многие в Штатах также думали, что отношения между Россией и США будут нормальные после развала Советского Союза. Однако произошло обратное.’}, {‘speaker’: ‘В.Путин’, ‘text’: ‘Запад боится сильного Китая больше, чем сильной России потому, что в России 150 миллионов человек, а в Китае – полтора миллиарда, и экономика Китая развивается семимильными шагами – пять с лишним процентов в год, было ещё больше. Но этого для Китая достаточно.’}, {‘speaker’: ‘Т.Карлсон’, ‘text’: ‘Вы были искренни тогда? Вы бы присоединились к НАТО?’}, {‘speaker’: ‘В.Путин’, ‘text’: ‘Послушайте, я задал вопрос: возможно это или нет? И получил ответ: нет. Если я был неискренним в своём желании выяснить позицию руководства…’}, {‘speaker’: ‘Т.Карлсон’, ‘text’: ‘Как Вы думаете, почему? Каковы мотивы этого? Я чувствую, что Вы испытываете горечь по этому поводу, я понимаю. Но почему, как Вы думаете, Запад тогда так вас оттолкнул? Откуда эта враждебность? Почему не удалось улучшить отношения? Каковы были мотивы этого, с Вашей точки зрения?’}, {‘speaker’: ‘В.Путин’, ‘text’: ‘Вы сказали, что я испытываю горечь от ответа. Нет, это не горечь, это просто констатация факта. Мы же не жених и невеста, горечь, обиды – это не те субстанции, которые в таких случаях имеют место быть. Просто мы поняли, что нас там не ждут, вот и всё. Хорошо, ладно. Но давайте будем выстраивать отношения по-другому, будем искать точки соприкосновения.’}]
Разговорные части интервью
В этом разделе мы разделяем разговорные фрагменты каждого участника интервью. Для этого мы используем регулярные выражения, а не LLM.
Здесь мы находим позиции имен участников в тексте интервью:
parts = list(filter(None, re.split(r"(Т.Карлсон:)|(Т.Карлсон \(как переведено\):)|(В.Путин:)", txtRU)))
parts = list(zip(parts[::2], parts[1::2]))
print("Total parts", len(parts))
print("First 4:")
for part in parts[:4]:
print(part)
Total parts 149
First 4:
('Т.Карлсон (как переведено):', ' Господин Президент, спасибо большое.\n24 февраля 2022 года Вы обратились к своей стране и нации, когда начался конфликт на Украине. Вы сказали, что действуете, потому что пришли к выводу, что с помощью НАТО США могут начать внезапную атаку, нападение на вашу страну. Для американцев это подобно паранойе.\nПочему Вы считаете, что Америка могла нанести неожиданный удар по России? Как Вы пришли к такому выводу?\n')
('В.Путин:', ' Дело не в том, что Америка собиралась наносить неожиданный удар по России, я так и не говорил.\nУ нас с Вами ток-шоу или у нас серьёзный разговор?\n')
('Т.Карлсон:', ' Это прекрасная цитата. Спасибо.\nУ нас серьёзный разговор.\n')
('В.Путин:', ' У Вас базовое образование историческое, насколько я понимаю, да?\n')
Разделите текст интервью на разговорные части:
parts2 = [(('Т.Карлсон' if 'Карлсон' in part[0] else 'В.Путин'), part[1].strip()) for part in parts]
pd.DataFrame(parts2)
0
1
0
Т.Карлсон
Господин Президент, спасибо большое.\n24 февраля 2022 года Вы обратились к своей стране и нации, когда начался конфликт на Украине. Вы сказали, что действуете, потому что пришли к выводу, что с помощью НАТО США могут начать внезапную атаку, нападение на вашу страну. Для американцев это подобно паранойе.\nПочему Вы считаете, что Америка могла нанести неожиданный удар по России? Как Вы пришли к такому выводу?
1
В.Путин
Дело не в том, что Америка собиралась наносить неожиданный удар по России, я так и не говорил.\nУ нас с Вами ток-шоу или у нас серьёзный разговор?
2
Т.Карлсон
Это прекрасная цитата. Спасибо.\nУ нас серьёзный разговор.
3
В.Путин
У Вас базовое образование историческое, насколько я понимаю, да?
4
Т.Карлсон
Да.
…
…
…
144
Т.Карлсон
Не считаете ли Вы, что было бы слишком унизительно для НАТО сейчас признать за Россией контроль того, что два года назад составляло украинскую территорию?
145
В.Путин
А я же сказал: пусть подумают, как сделать это достойно. Варианты есть, но если желание есть.\nДо сих пор шумели, кричали: надо добиться стратегического поражения России, поражения на поле боя… Но теперь, видимо, осознание приходит, что это непросто сделать, если вообще возможно. По моему мнению, это невозможно по определению, этого не будет никогда. Мне кажется, сейчас осознание этого пришло и к тем, кто контролирует власть на Западе. Но если это так и если это осознание пришло, подумайте теперь, что делать дальше. Мы готовы к этому диалогу.
146
Т.Карлсон
Готовы ли Вы сказать, например, НАТО: поздравляю, вы победили, давайте ситуацию сохраним в том виде, в каком она сейчас.
147
В.Путин
Знаете, это предмет переговоров, которые с нами никто не хочет вести или, точнее сказать, хотят, но не знают как. Знаю, что хотят, – я не только вижу это, но я знаю, что хотят, но никак не могут понять, как это сделать. Додумались же, довели до той ситуации, в которой мы находимся. Это не мы довели, а наши «партнёры», оппоненты до этого довели. Хорошо, пусть теперь подумают, как это повернуть в другую сторону. Мы же не отказываемся.\nБыло бы смешно, если бы не было так грустно. Эта бесконечная мобилизация на Украине, истерика, внутренние проблемы, всё это… Рано или поздно всё равно мы договоримся. И знаете что? Может, даже странно в сегодняшней ситуации прозвучит: всё равно отношения между народами восстановятся. Потребуется много времени, но это восстановится.\nСовсем приведу необычные примеры. На поле боя происходит боестолкновение, конкретный пример: украинские солдаты попали в окружение – это конкретный пример из жизни, боевые действия – наши солдаты им кричат: «Шансов нет, сдавайтесь! Выходите, будете живы, сдавайтесь!». И вдруг оттуда на русском, хорошем русском языке кричат: «Русские не сдаются!» – и все погибли. Они до сих пор русскими себя ощущают.\nВ этом смысле то, что происходит, это в известной степени элемент гражданской войны. И все думают на Западе, что боевые действия навсегда растащили одну часть русского народа от другой. Нет. Воссоединение произойдёт. Оно никуда и не делось.\nПочему украинские власти растаскивают Русскую православную церковь? Потому что она объединяет не территорию, а душу, и никому не удастся её разделить.\nЗакончим или что-то ещё?
148
Т.Карлсон
У меня тогда всё.\nСпасибо большое, господин Президент.
149 rows × 2 columns
Замечание: Мы предполагаем, что части, произнесенные участниками, имеют соответствующий порядок и количество. Здесь объединены произнесенные части и табулированы первые 6:
tcQuestions = [part[1] for part in parts2 if 'Карлсон' in part[0] and part[1].endswith('?')]
len(tcQuestions)
56
Здесь мы приводим таблицу всех произнесенных Такером Карлсоном частей речи (и считаем все из них “вопросами”):
multi_column(tcQuestions, 3)
0
1
2
0
Господин Президент, спасибо большое.\n24 февраля 2022 года Вы обратились к своей стране и нации, когда начался конфликт на Украине. Вы сказали, что действуете, потому что пришли к выводу, что с помощью НАТО США могут начать внезапную атаку, нападение на вашу страну. Для американцев это подобно паранойе.\nПочему Вы считаете, что Америка могла нанести неожиданный удар по России? Как Вы пришли к такому выводу?
Что такое денацификация? Что это означает?
Я думаю, что это действительно справедливая оценка.\nСледующий вопрос. Может быть, Вы обменяли одну колониальную державу на другую, но более такую щадящую? Может быть, БРИКС сегодня в опасности того, что более добрая колониальная держава – Китай, будет там доминировать? Это хорошо ли для суверенитета, как Вы думаете? Вас беспокоит это?
1
Когда это было, в какие годы?
Вы будете удовлетворены той территорией, которая у вас есть уже сейчас?
Вы минуту назад сказали, что сегодня мир будет намного лучше, если там не будет двух конкурирующих союзов-альянсов, которые друг с другом конкурируют. Может быть, сегодняшняя американская администрация, как Вы говорите, как Вы считаете, настроена против Вас, но, может быть, следующая администрация в США, правительство после Джо Байдена, захочет наладить с Вами связи и Вы с ними захотите наладить связи? Или это не играет роли?
2
Можно спросить? Вы говорите, что часть Украины на самом деле является русскими землями сотни лет. Почему тогда, когда Вы стали Президентом, вы просто не взяли их, 24 года назад? У вас ведь и оружие было. Почему Вы тогда так долго ждали?
А что Вы будете с этим делать? Гитлера уже 80 лет нет в живых, нацистской Германии больше не существует, это правда. Вы говорите, что вы хотите потушить этот пожар украинского национализма. Как это сделать?
Вы описываете две разные системы, говорите, что лидер действует в интересах избирателей, но в то же время какие-то решения правящими классами принимаются. Вы страну возглавляете много лет, как Вы думаете, с Вашим опытом, кто в Америке принимает решения?
3
В 1654 году?
Хорошо. Я, конечно, не защищаю нацизм или неонацизм. Но мой вопрос в практическом плане: вы не контролируете всю страну, и мне кажется, будто вы хотите всю её контролировать. Но каким образом вы сможете тогда выкорчевать идеологию, культуру, какие-то чувства, историю в стране, которую вы не контролируете? Каким образом этого достигнуть?
Должен спросить. Вы чётко сказали, что расширение НАТО стало нарушением обещаний и является угрозой вашей стране. Но до того, как Вы отправили войска на Украину, на конференции по безопасности, вице-президент США поддержал стремление Президента Украины вступить в НАТО. Вы думаете, что это в том числе спровоцировало военные действия?
4
У Вас энциклопедические знания. Но почему первые 22 года своего президентства Вы об этом не говорили?
Будут ли переговоры? И почему до сих пор таких переговоров – мирных переговоров – относительно урегулирования конфликта на Украине не было?
Вы думаете, что у Зеленского есть свобода, для того чтобы вести переговоры по урегулированию этого конфликта?
5
А как Вы думаете, есть ли у Венгрии право забрать свои земли? И другие нации могут ли забрать свои земли и, может быть, вернуть Украину к границам 1654 года?
Да, но Вы не будете говорить с украинским Президентом, Вы будете говорить с американским Президентом. Когда Вы в последний раз разговаривали с Джо Байденом?
Считаете, что сейчас, в феврале 2024 года, у него есть свобода говорить с вашим Правительством, пытаться как-то своей стране помочь? Он может вообще сам это сделать?
6
Вы Орбану говорили об этом, что он может вернуть себе часть земель Украины?
Вы не помните?
Это хороший вопрос. Зачем он это сделал?
7
Да, я думаю, что такого много бывает. Скорее всего, многие страны недовольны переменой границ во время изменений в XX веке и до того. Но дело в том, что Вы ничего подобного не заявляли ранее, до февраля 2022 года. И Вы говорили о том, что Вы чувствовали физическую угрозу со стороны НАТО, в частности, ядерную угрозу, и это побудило Вас действовать. Правильно ли я Вас понимаю?
А что он сказал?
Вы описали связь между Россией и Украиной, описали Россию, что это православная страна, Вы говорили об этом. А что это значит для Вас? Вы лидер христианской страны, как Вы сами себя описываете. Какой эффект это имеет на Вас?
8
Вы были искренни тогда? Вы бы присоединились к НАТО?
Но с тех пор Вы с ним не разговаривали – после февраля 2022 года?
Если позволите, религии отличаются. Дело в том, что христианство – ненасильственная религия, Христос говорит: «подставить другую щеку», «не убий» и так далее. А каким образом лидер может быть христианином, если приходится убивать кого-то другого? Как можно это примирить в себе?
9
А если бы он сказал «да», Вы бы присоединились к НАТО?
Как Вы считаете, обеспокоено ли НАТО тем, что это всё может перерасти в глобальную войну или даже в ядерный конфликт?
То есть Вы считаете, что тут что-то сверхъестественное действует? Когда Вы смотрите на происходящее в мире, видите ли Вы дела Господни? Говорите ли Вы себе, что тут я вижу действия каких-то сверхчеловеческих сил?
10
Как Вы думаете, почему? Каковы мотивы этого? Я чувствую, что Вы испытываете горечь по этому поводу, я понимаю. Но почему, как Вы думаете, Запад тогда так вас оттолкнул? Откуда эта враждебность? Почему не удалось улучшить отношения? Каковы были мотивы этого, с Вашей точки зрения?
Вы имеете в виду угрозу российского вторжения, например, в Польшу или в Латвию? Вы можете представить сценарий, когда вы направите российские войска в Польшу?
Но когда тогда начнётся империя ИИ – искусственного интеллекта?
11
Оппозиция вам?
Аргумент – я думаю, Вы хорошо знаете – заключается вот в чём: да, вот он вторгся в Украину, у него есть территориальные притязания на всём континенте. Вы недвусмысленно говорите о том, что таких притязаний территориальных у вас нет?
Что Вы об этом думаете?
12
Когда это было, в каком году?
Один из старших сенаторов – Чак Шумер, кажется, вчера сказал: нам необходимо продолжать финансировать Украину, или же в конце концов американским солдатам придётся воевать на Украине вместо Украины. Как Вы оцениваете такое заявление?
Спасибо Вам большое за то время, которое Вы уделили. Я хочу задать ещё один вопрос.\nЭван Гершкович, ему 32 года, американский журналист, он находится в заключении уже более года, это большая история в США. Я хочу спросить у Вас: Вы готовы в качестве жеста доброй воли освободить его, для того чтобы мы отвезли его в США?
13
То есть Вы дважды описывали, как американские президенты принимали какие-то решения, а потом их команды эти решения пускали под откос?
Кто взорвал «Северный поток»?
Конечно, всё происходит в течение веков – страна ловит шпиона, задерживает его и потом обменивает на кого-то. Конечно, это не моё дело, но отличается эта ситуация тем, что этот человек совершенно точно не шпион – это просто ребёнок. И, может, он, конечно, нарушил ваше законодательство, однако он не шпион и совершенно точно не шпионил. Может быть, он находится всё-таки в другой категории? Может быть, несправедливо было бы просить в обмен на него кого-то другого?
14
То есть он торговал больше с Россией, чем с Европейским союзом, Украина?
У Вас есть свидетельство того, что НАТО или же ЦРУ сделали это?
Честно говоря, с войной, я не знаю, работает это или нет. Если позволите, я задам ещё один вопрос.\nМожет быть, Вы не хотите отвечать по стратегическим причинам, однако не беспокоитесь ли Вы, что происходящее на Украине может привести к чему-то куда более масштабному и куда более страшному? И насколько Вы готовы, Вы замотивированы позвонить, например, в Штаты и сказать: давайте договариваться?
15
При поддержке кого?
Но я не совсем понимаю. Это крупнейший акт промышленного терроризма за всю историю и, более того, крупнейший выброс СО2 в атмосферу. Но с учётом того, что у Вас есть свидетельства и у Ваших спецслужб, почему Вы не представите такие свидетельства и не победите в этой войне пропаганды?
Да, Вы об этом уже сказали. Я прекрасно понимаю, конечно, что это не ругательство. И в самом деле сообщалось о том, что Украине не дали подписать мир по указанию бывшего премьер-министра Великобритании, который действовал по указке из Вашингтона. Вот почему я спрашиваю, почему Вам напрямую не решать эти вопросы с администрацией Байдена, который контролирует администрацию Зеленского на Украине?
16
То есть это было за восемь лет до начала конфликта. А что спровоцировало этот конфликт, когда Вы решили, что вам нужно всё-таки сделать этот шаг?
Да, но вот вопрос – Вы работали в Германии, об этом хорошо известно, и немцы чётко понимают, что их партнёры по НАТО это сделали, конечно, это нанесло удар по экономике ФРГ, – почему же тогда немцы молчат? Это приводит меня в замешательство: почему немцы ничего не говорили по этому вопросу?
Хочу удостовериться, что я Вас правильно понимаю. То есть Вы хотите добиться путём переговоров решения того, что происходит сейчас на Украине, правильно?
17
Вы говорили с Госсекретарём, с Президентом? Может быть, они боялись с Вами разговаривать? И говорили Вы им, что если они будут продолжать накачивать Украину оружием, то Вы будете действовать?
Может быть, мир сейчас разделяется на два полушария: одно полушарие с дешёвой энергией, другое – нет.\nЯ хочу задать вопрос: сейчас многополярный мир – Вы можете описать альянсы, блоки, кто на чьей стороне, как Вы считаете?
Не считаете ли Вы, что было бы слишком унизительно для НАТО сейчас признать за Россией контроль того, что два года назад составляло украинскую территорию?
18
Как Вы думаете, удалось вам сейчас её прекратить? Достигли ли вы своих целей?
Приведу один пример. Американский доллар объединил весь мир во многом. Как Вы считаете, исчезнет ли доллар как резервная валюта? Каким образом санкции изменили место доллара в мире?
None
Поисковая система
В этом разделе мы создадим (мини) поисковую систему из частей интервью, полученных выше.
Вот шаги:
Убедитесь, что части интервью связаны с уникальными идентификаторами, которые также идентифицируют говорящих.
Найдите векторы вкраплений для каждой части.
Создайте рекомендательную функцию, которая:
Фильтрует вкрапления в соответствии с заданным типом
Находит векторное вложение заданного запроса
Находит точечные произведения вектора запроса и векторов частей
Выбирает лучшие результаты
Здесь мы создаем ассоциацию частей интервью, полученных выше:
k = 0
parts = {f"{k} {key}": value for k, (key, value) in enumerate(parts)}
len(parts)
149
Здесь мы находим LLM-векторы вкраплений частей интервью:
from openai import OpenAI
client = OpenAI()
embs = {key: client.embeddings.create(input=value, model = "text-embedding-3-large").data[0].embedding for key, value in parts.items()}
len(embs)
Вот функция для поиска наиболее релевантных частей интервью по заданному запросу (с использованием точечного произведения):
def top_parts(query, n=3, type='answers'):
vec = client.embeddings.create(input=query, model = "text-embedding-3-large").data[0].embedding
if type is None:
type = 'part'
if type in ['part', 'statement']:
embsLocal = embs
elif type in ['answer', 'answers', 'Putin', 'Путин']:
embsLocal = {key: value for key, value in embs.items() if 'Путин' in key}
elif type in ['question', 'questions', 'Carlson', 'Tucker', 'Карлсон']:
embsLocal = {key: value for key, value in embs.items() if 'Карлсон' in key}
else:
raise ValueError(f"Do not know how to process the {type} argument.")
sres = {key: sum([v1*v2 for v1, v2 in zip(value, vec)]) for key, value in embsLocal.items()}
sres = sorted(sres.items(), key=lambda x: -x[1])
return [{'Score': score, 'Text': parts[key]} for key, score in sres[:n]]
Я был занят в тот день. Я не взрывал « Северный поток ».\n
2
0.508881
Меня это тоже удивляет. Но сегодняшнее немецкое руководство не руководствуется национальными интересами, а руководствуется интересами коллективного Запада, иначе трудно объяснить логику их действий или бездействия. Ведь дело не только в « Северном потоке – 1», который взорвали. « Северный поток – 2» повредили, но одна труба жива-здорова, и по ней можно подавать газ в Европу, но Германия же не открывает его. Мы готовы, пожалуйста.\nЕсть ещё один маршрут через Польшу, Ямал – Европа называется, тоже большой поток можно осуществлять. Польша закрыла его, но Польша с руки клюет у немцев, из общеевропейских фондов деньги получает, а основной донор в эти общеевропейские фонды – Германия. Германия кормит Польшу в известной степени. А те взяли и закрыли маршрут на Германию. Зачем? Не понимаю.\nУкраина, в которую немцы поставляют оружие и деньги дают. Второй спонсор после Соединённых Штатов по объёмам финансовой помощи Украине – это Германия. Через территорию Украины два маршрута газовых проходят. Они взяли один маршрут закрыли просто, украинцы. Откройте второй маршрут и, пожалуйста, получайте газ из России. Они же не открывают.\nПочему немцам не сказать: «Послушайте, ребята, мы вам и деньги даём, и оружие. Вентиль отвинтите, пожалуйста, пропустите из России газ для нас. Мы втридорога покупаем сжиженный газ в Европе, это роняет уровень нашей конкурентоспособности, экономики в целом до нуля. Вы хотите, чтобы мы деньги вам давали? Дайте нам нормально существовать, заработать нашей экономике, мы же вам деньги оттуда даём». Нет, не делают этого. Почему? Спросите у них. (Стучит по столу.) Что здесь, что в голове у них – одно и то же. Там люди очень некомпетентные.\n
res2 = top_parts('Где проходили российско-украинские переговоры?', 2, type = 'answer')
tbl2 = pd.DataFrame(res2).to_html()
display(Markdown(re.sub(r"(перег\w+)", r'<span style="color: orange"> \1 </span>', tbl2)))
Score
Text
0
0.516948
Они были, они дошли до очень высокой стадии согласования позиций сложного процесса, но всё-таки они были практически завершены. Но после того, как мы отвели войска от Киева, я уже сказал, другая сторона, Украина, выбросила все эти договорённости и приняла под козырёк указания западных стран – европейских, Соединённых Штатов – воевать с Россией до победного конца.\nИ больше того: Президент Украины законодательно запретил вести переговоры с Россией. Он подписал декрет, запрещающий всем вести переговоры с Россией. Но как мы будем вести переговоры , если он сам себе запретил и всем запретил? Мы знаем, что он выдвигает какие-то идеи по поводу этого урегулирования. Но для того, чтобы о чём-то договариваться, нужно вести диалог, не так ли?\n
1
0.430809
Мы постоянно об этом говорили. Мы обращались к руководству Соединённых Штатов, европейских стран, чтобы этот процесс прекратился немедленно, чтобы были исполнены Минские соглашения. Откровенно говоря, я не знал, как мы это сделаем, но я был готов исполнять. Они сложные для Украины, там очень много элементов независимости для Донбасса, для этих территорий было предусмотрено, это правда. Но я был уверен абсолютно, я и сейчас Вам скажу: я искренне считал, что если всё-таки удастся уговорить тех людей, которые на Донбассе живут, – их надо было ещё уговорить возвратиться в рамки украинской государственности, – то постепенно, постепенно раны заживут. Постепенно, когда эта часть территории вернётся в хозяйственную жизнь, в общую социальную среду, когда пенсии будут платить, социальные пособия – всё постепенно, постепенно срастётся. Нет, никто этого не хотел, все хотели только с помощью военной силы решить вопрос. Но этого мы не могли позволить.\nИ всё дошло до этой ситуации, когда на Украине объявили: нет, мы не будем ничего [исполнять]. Начали ещё подготовку к военным действиям. Войну начали они в 2014 году. Наша цель – прекратить эту войну. И мы не начинали её в 2022-м, это попытка её прекратить.\n
Стилизованные вариации
В этом разделе мы покажем, как можно перефразировать разговорные фрагменты в стиле некоторых политических знаменитостей.
Карлсон -> Клинтон
Здесь приведены примеры использования LLM для перефразирования вопросов Такера Карлсона в стиле Хиллари Клинтон:
for _ in range(2):
q = random.choice(tcQuestions)
print('=' * 100)
print("Такер Карлсон:", q)
print('-' * 100)
q2 = llm_synthesize(["Перефразируйте этот вопрос в стиле Хиллари Клинтон:", q])
print("Хиллари Клинтон:", q2)
====================================================================================================
Такер Карлсон: Да, но вот вопрос – Вы работали в Германии, об этом хорошо известно, и немцы чётко понимают, что их партнёры по НАТО это сделали, конечно, это нанесло удар по экономике ФРГ, – почему же тогда немцы молчат? Это приводит меня в замешательство: почему немцы ничего не говорили по этому вопросу?
----------------------------------------------------------------------------------------------------
Хиллари Клинтон: Ваше пребывание в Германии было широко известно, и немцы хорошо осознают, что их союзники в НАТО также принимали участие в этом. Очевидно, что это негативно сказалось на экономике ФРГ. Однако, я задаюсь вопросом: почему немцы не высказывали своего мнения по этому вопросу? Это вызывает у меня некоторое замешательство, и я хотела бы понять, почему немцы предпочли молчать на эту тему.
====================================================================================================
Такер Карлсон: То есть это было за восемь лет до начала конфликта. А что спровоцировало этот конфликт, когда Вы решили, что вам нужно всё-таки сделать этот шаг?
----------------------------------------------------------------------------------------------------
Хиллари Клинтон: Таким образом, прошло восемь лет до возникновения конфликта. Что послужило причиной этого конфликта и заставило вас принять решение о необходимости сделать этот шаг?
Путин -> Трамп
Вот примеры использования LLM для перефразирования ответов Владимира Путина в стиле Дональда Трампа:
for _ in range(2):
q = random.choice([value for key, value in parts.items() if 'Путин' in key])
print('=' * 100)
print("Владимир Путин:", q)
print('-' * 100)
q2 = llm_synthesize(["Перефразируйте этот ответ в стиле Дональда Трампа:", q])
print("Дональд Трамп:", q2)
====================================================================================================
Владимир Путин: Нет, мы пока не достигли своих целей, потому что одна из целей – это денацификация. Имеется в виду запрещение всяческих неонацистских движений. Это одна из проблем, которую мы обсуждали и в ходе переговорного процесса, который завершился в Стамбуле в начале прошлого года, но не по нашей инициативе завершился, потому что нам – европейцы, в частности – говорили: нужно обязательно создать условия для окончательного подписания документов. Мои коллеги во Франции и Германии говорили: «Как ты себе представляешь, как они будут подписывать договор: с пистолетом, приставленным к виску? Надо отвести войска от Киева». Говорю: хорошо. Мы отвели войска от Киева.
Как только мы отвели войска от Киева, сразу же наши украинские переговорщики выбросили в помойку все наши договорённости, достигнутые в Стамбуле, и приготовились к длительному вооружённому противостоянию при помощи Соединённых Штатов и их сателлитов в Европе. Вот как ситуация развивалась. И так, как она выглядит сейчас.
----------------------------------------------------------------------------------------------------
Дональд Трамп: Нет, мы не достигли наших целей. Одна из наших целей - денацификация, запрещение неонацистских движений. Мы обсуждали это на переговорах в Стамбуле, но они не завершились по нашей инициативе. Европейцы говорили, что нужно создать условия для окончательного подписания документов. Мы отвели войска от Киева, но украинские переговорщики отвергли наши договоренности и готовятся к вооруженному противостоянию с помощью США и их союзников в Европе. Это то, что происходит сейчас.
====================================================================================================
Владимир Путин: При этом Сталин настаивал на том, чтобы эти республики, которые образовывались, входили в качестве автономных образований, но почему-то основатель Советского государства, Ленин, настоял на том, чтобы они имели право выхода из состава Советского Союза. И, тоже по непонятным причинам, наделил образующуюся советскую Украину землями, людьми, проживавшими на этих территориях, даже если они раньше никогда не назывались Украиной, почему-то при формировании всё это было «влито» в состав Украинской ССР, в том числе всё Причерноморье, которое было получено во времена Екатерины II и, собственно, к Украине никогда никакого исторического отношения не имело.
Даже если мы вспомним, назад вернёмся, 1654 год, когда эти территории вернулись в состав Российской империи, там было три-четыре современные области Украины, никакого Причерноморья там и близко не было. Просто не о чем было говорить.
----------------------------------------------------------------------------------------------------
Дональд Трамп: Странно, но Сталин настаивал на том, чтобы эти новые республики были автономными, в то время как Ленин хотел, чтобы они имели право выхода из Советского Союза. И что еще страннее, Ленин передал Украине земли и людей, которые никогда не были частью Украины. Все эти земли, включая Причерноморье, были получены во времена Екатерины II и никогда не имели исторической связи с Украиной. Если мы вернемся в 1654 год, когда эти территории вернулись в Российскую империю, там не было никакого Причерноморья. Просто ничего не было.
Ссылки
Ссылки даны на английском языке, поскольку именно на этом языке они были созданы, и по английским названиям их легче искать.