
About Me
데이터가 잘 흐르고 다양하게 활용 될 수 있도록 꿈꾸고 실현하는 5년차 데이터 엔지니어 최승호입니다.
어떻게 하면 안정적인 데이터 파이프라인을 구축할 지,
어떻게 하면 비용효율적으로 데이터 플랫폼을 구성할 지,
어떻게 하면 데이터 분석에 집중할 수 있는 환경을 제공할 지
지속적으로 고민하고 테스트하고 도입하는 데이터 엔지니어입니다.
데이터를 통해 인사이트를 낼 수 있다고 생각하며 그 가치가 무궁무진하다고 믿습니다.
조직이 공통된 목표를 향해 나아갈 수 있도록 중간에서 커뮤니케이션하며 업무를 진행하여 인사이트를 내는데 도움이 되기를 희망합니다.
Experience
Data Engineer
Neowiz
실시간(CDC) 데이터 파이프라인 구축 및 데이터 웨어하우스 운영
- 🔄 15개 이상 다양한 데이터 소스 통합 및 일 10억건+ CDC ETL 구축
- 📊 Redshift 멀티클러스터 아키텍처 설계로 성능 병목 해결 및 데이터 매쉬 구조 초석 마련
- 🏗️ 멀티클라우드(AWS ↔ GCP)간 일 4000만건+ 실시간 데이터 파이프라인 구축
- 🧊 Trino와 Iceberg를 활용한 데이터 레이크 아키텍처 설계 및 구축
- ⚡ 자동화 및 모니터링 시스템으로 운영 리소스 90% 절감
- 💰 인프라 비용 최적화로 고정비용 20%($3,000+) 절감
- 🤖 LLM 기반 Text-to-SQL 시스템으로 데이터 추출 요청 40% 감소
Projects
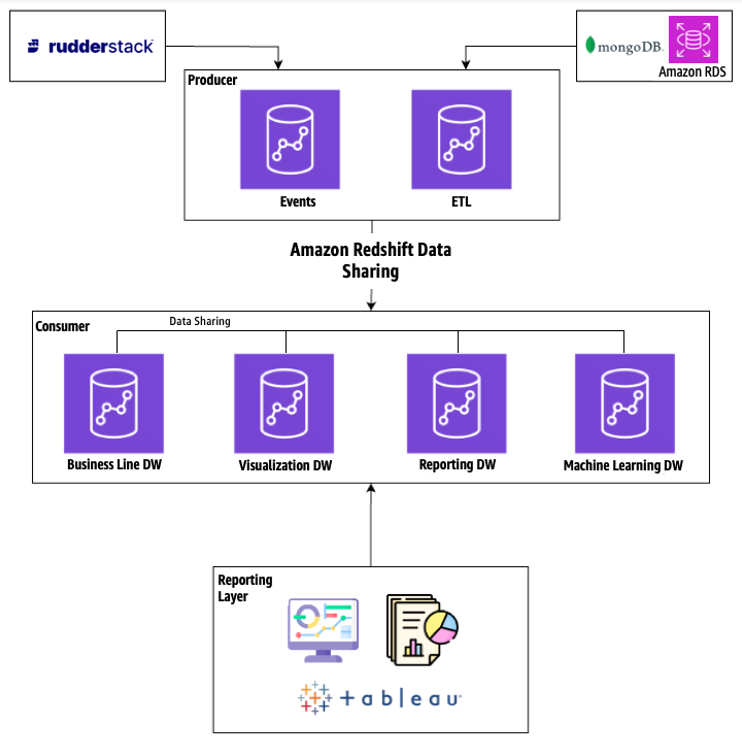
AWS 멀티 클러스터 아키텍처 도입 (GAMES ON AWS 2024 발표)
2024.01 - 2024.06단일 Redshift 클러스터의 성능 병목을 해결하기 위한 멀티클러스터 아키텍처 설계 및 구축. Redshift Serverless 및 Concurrency Scaling 도입으로 비용 최적화와 성능 향상을 동시에 달성
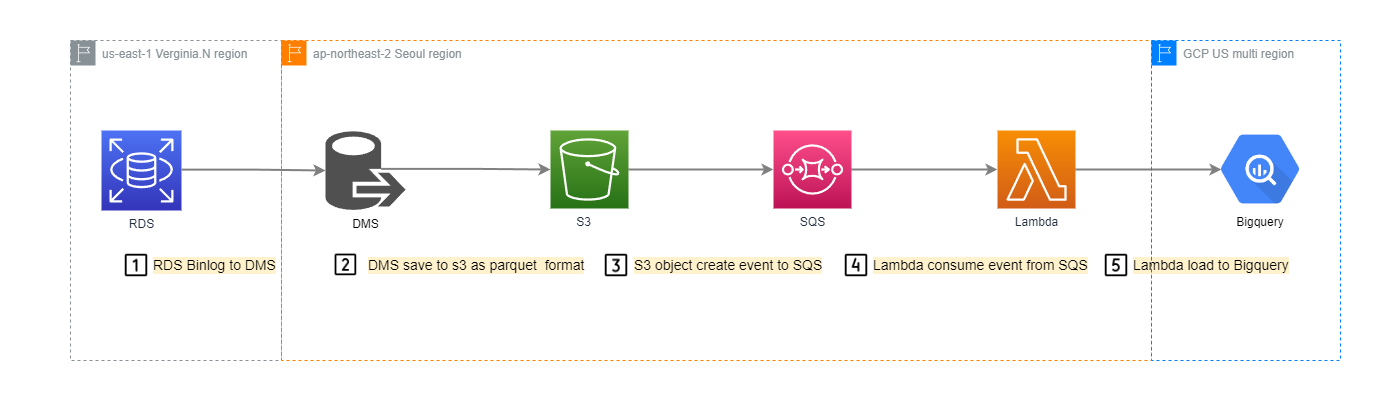
Multi-Cloud Real-time Data Pipeline (AWS ↔ GCP)
2022.12 - 2023.05AWS DMS CDC, Lambda, SQS를 활용하여 RDS Aurora의 데이터를 Google BigQuery로 준실시간 이동하는 멀티클라우드 파이프라인 구축. 일 4,000만 건 데이터 처리로 실시간 분석 및 FDS 지원

Trino on ECS 기반 DataLake 플랫폼
2023.08 - 2024.01Trino를 AWS ECS에 배포하여 다양한 데이터 소스를 통합 쿼리할 수 있는 DataLake 환경 구축. Apache Iceberg 테이블 포맷을 활용한 원본 데이터 확인 및 Federated Query 플랫폼 제공
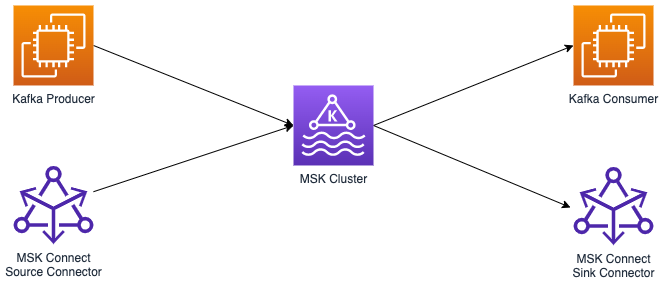
스트리밍 데이터 수집
2025.01 - 2025.05Amazon MSK와 DynamoDB에서 생성되는 스트리밍 데이터 수집 및 처리 플랫폼 구축. 실시간 이벤트 스트림 처리와 반정형 데이터 처리
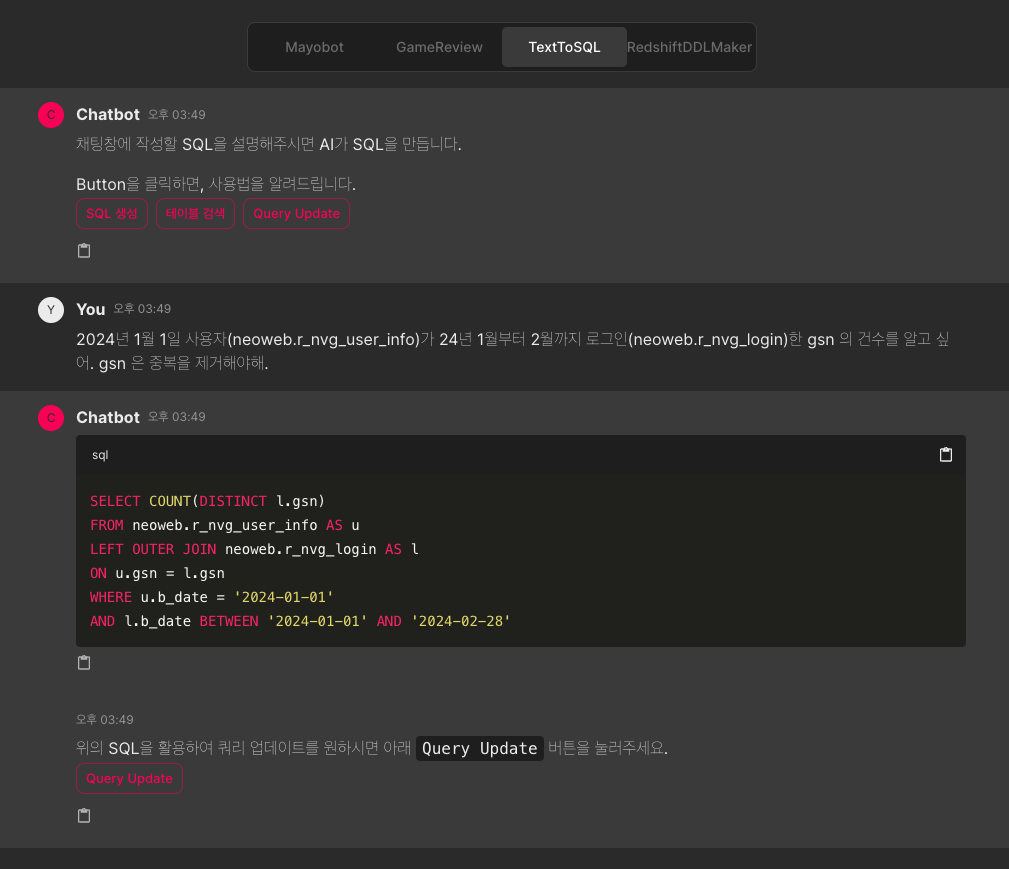
LLM 기반 Text-to-SQL 시스템
2024.01 - 2024.04LangChain과 OpenAI GPT를 활용한 자연어 기반 SQL 생성 시스템 구축. 비개발자도 쉽게 데이터 조회가 가능하도록 하여 데이터 추출 요청을 감소시킨 솔루션
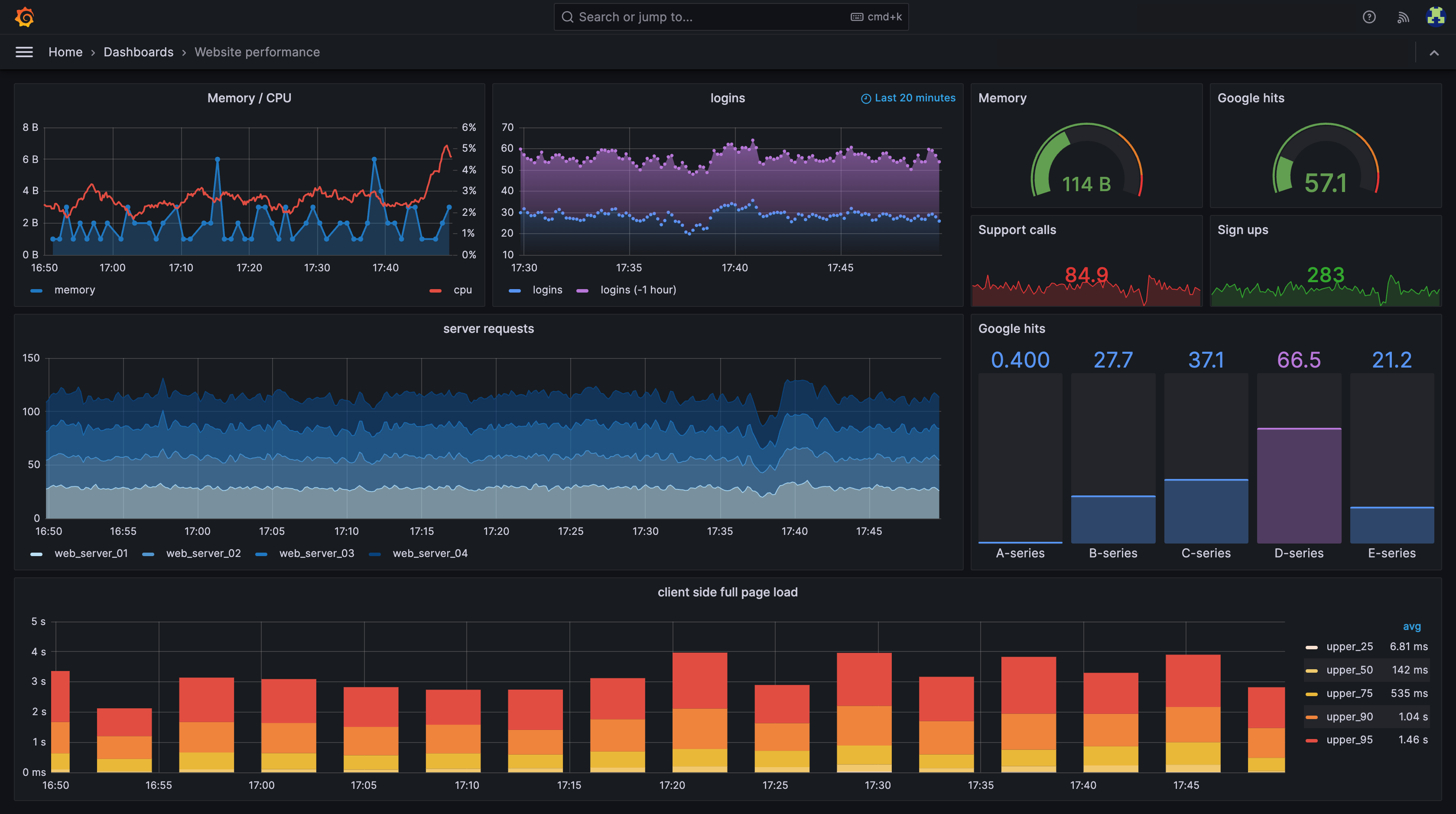
인프라 운영 및 모니터링 시스템
2021.01 -IaC 기반 인프라 관리와 종합적인 모니터링 시스템 구축. Terraform과 Serverless Framework를 통한 인프라 코드화 및 비용 최적화 자동화 시스템 도입
다양한 데이터 소스 통합
2021.01 -ElasticSearch, Google/Apple 마켓, Prometheus, Redis, SensorTower 등 15개 이상의 다양한 외부 데이터 소스를 안정적으로 수집하는 ETL 구축

기타 프로젝트
2020.07 -Snowflake PoC, 마케팅 비용 관리 사이트 개발, 외부 API 구축, 공용 라이브러리 개발, ML(첫 구매자 예측, 이탈자 예측) 관련 배포 다양한 프로젝트 수행 및 조직 내 데이터 문화 확산