
一个 Web 请求进来,代码要查数据库、调远程接口、读写文件。按传统的同步写法,这个请求会占住一个平台线程,哪怕大部分时间都在等 I/O。
线程池能缓解线程创建成本,但不能改变一个事实:平台线程数量仍然受操作系统线程数量、内存和调度成本限制。当并发请求继续增加时,线程池里的线程会被排队任务占满,吞吐量很快卡住。
虚拟线程就是为这个问题来的。它让我们继续用简单的同步阻塞代码,同时让等待 I/O 的任务不再长期占着昂贵的平台线程。
虚拟线程(Virtual Thread)是 Java 21 正式引入的一种轻量级线程,也是 java.lang.Thread 的一种实现。它由 JDK 管理和调度,而不是直接和某个操作系统线程一一绑定。
平台线程(Platform Thread)通常是对操作系统线程的薄封装。一个平台线程运行时,会在整个生命周期内占用一个操作系统线程。虚拟线程不一样:它运行 Java 代码时需要挂载到某个平台线程上;当它执行可挂起的阻塞操作时,JDK 可以把它从平台线程上卸载下来,让这个平台线程去执行别的虚拟线程。
因此,虚拟线程的数量可以远大于平台线程数量。官方文档里用虚拟内存做类比:操作系统把大量虚拟地址映射到有限物理内存,Java 运行时则把大量虚拟线程映射到较少的平台线程。
虚拟线程的几个关键点:
- 虚拟线程仍然是
Thread,支持ThreadLocal、中断、异常栈、调试和 JFR 观测。 - 虚拟线程适合大量阻塞等待的任务,比如 HTTP 调用、数据库查询、消息队列访问、文件或网络 I/O。
- 虚拟线程不是更快的 CPU 执行单元,不会让一段纯计算代码跑得更快。
- 虚拟线程很便宜,通常应该“每个任务一个虚拟线程”,而不是像平台线程一样池化复用。
在 Java 里,虚拟线程、平台线程和操作系统线程大致是这样的关系:
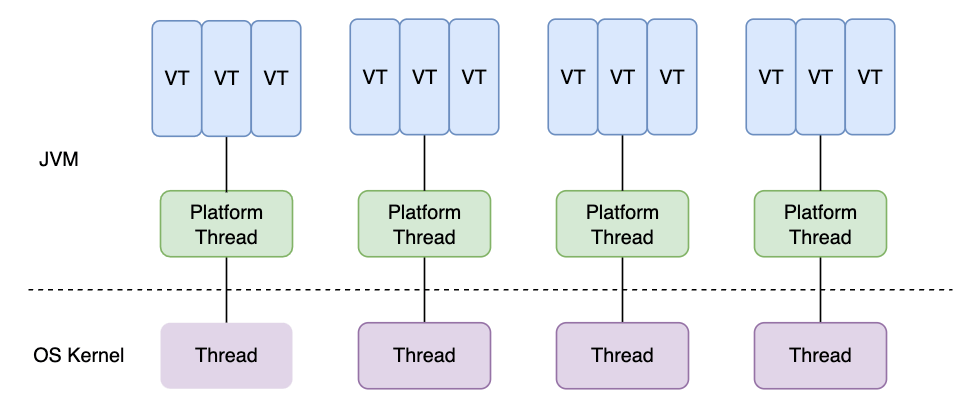
在 Windows、Linux 等主流操作系统中,HotSpot JVM 的平台线程通常采用一对一线程模型,也就是一个平台线程对应一个操作系统线程。虚拟线程引入后,JDK 在平台线程之上又加了一层调度:
- 虚拟线程是任务的承载者,业务代码看到的
Thread.currentThread()返回的是虚拟线程本身。 - 平台线程是虚拟线程的载体(Carrier Thread),负责真正执行虚拟线程里的 Java 代码。
- 操作系统仍然只调度平台线程,不知道虚拟线程的存在。
一个虚拟线程开始执行时,会被 JDK 调度器挂载(mount)到某个平台线程上。执行到阻塞 I/O、BlockingQueue.take()、Future.get() 等支持挂起的阻塞点时,虚拟线程可以卸载(unmount),平台线程被释放出来继续执行其他虚拟线程。等阻塞操作就绪后,虚拟线程再被提交回调度器,挂载到某个平台线程上继续执行。
这个挂载和卸载过程对业务代码是透明的。你写的仍然是普通同步代码:
String body = httpClient.send(request, BodyHandlers.ofString()).body();
Result result = repository.query(body);
return service.handle(result);如果这些调用内部发生阻塞,虚拟线程可以挂起自己;如果换成平台线程,这个线程会一直占住对应的操作系统线程。
Project Loom 是 OpenJDK 中改进 Java 并发模型的项目,虚拟线程是 Loom 最重要的成果之一。虚拟线程先后在 JDK 19、JDK 20 中预览,最终通过 JEP 444 在 JDK 21 转正。
Loom 不只是加了一个轻量级线程 API。它还推动了 JDK 阻塞 I/O、调试、JFR、线程转储等配套能力的调整,让传统的 thread-per-request 编程风格在高并发 I/O 场景下重新变得可扩展。
这也是虚拟线程和普通“协程库”的一个重要区别:虚拟线程被纳入了 Java 平台的线程模型。调试器、Profiler、JFR、线程 dump 都能以线程为单位理解它,而不是把业务调用链拆成一堆回调阶段。
很多服务端程序天然适合“一个请求一个线程”的模型。它的好处很明显:代码顺序执行,异常可以沿着调用栈抛出,调试器能一步步跟进去,线程 dump 也能看到请求卡在哪里。
问题在于平台线程太贵。
假设一个接口平均耗时 50ms,系统要达到 2000 QPS,按 Little's Law 粗略估算,需要同时处理约 100 个请求。如果接口平均耗时变成 500ms,同样 2000 QPS 就需要约 1000 个并发请求。每个请求都占一个平台线程时,线程数量很容易先于 CPU、网络带宽、数据库连接等资源成为瓶颈。
异步编程、Reactive 编程可以把线程从等待 I/O 中释放出来,但代价也很明显:调用链被拆成回调、CompletableFuture 链或响应式流水线,异常处理、调试、火焰图和线程上下文都会变复杂。
虚拟线程试图保留同步代码的可读性,同时降低阻塞等待时占用平台线程的成本。它提升的主要是吞吐能力和并发承载能力,不是单个请求的执行速度。
虚拟线程最适合下面这类任务:
- 并发任务数量很多,通常是成千上万级别。
- 任务大部分时间在等待 I/O,比如数据库、Redis、HTTP/RPC、消息队列、文件和网络读写。
- 现有代码主要是同步阻塞模型,不想为了扩展性改成复杂的异步链。
- 希望保留传统调用栈,方便调试、压测分析和线上排查。
典型场景包括:
- Spring MVC / Servlet 接口中调用数据库和外部 HTTP 服务。
- 后台任务批量调用第三方接口。
- 网关或聚合服务并发调用多个下游服务。
- 消息消费逻辑中包含阻塞式数据库写入或远程调用。
虚拟线程不适合把 CPU 密集型任务“变快”。如果任务主要是在算哈希、压缩图片、排序大数组、跑复杂规则引擎,线程数量超过 CPU 核心数之后,吞吐通常不会继续提高。CPU 密集型工作仍然应该关注算法、数据结构、批处理、并行流、专门的计算线程池或本地化优化。
JDK 21 中常见的创建方式有四种。
适合启动一个很简单的虚拟线程:
public class VirtualThreadDemo {
public static void main(String[] args) throws InterruptedException {
Thread thread = Thread.startVirtualThread(() -> {
System.out.println(Thread.currentThread());
});
thread.join();
}
}需要注意的是,虚拟线程是守护线程。如果 main 方法不等待它结束,JVM 可能直接退出,导致任务还没来得及执行完。
Thread.ofVirtual() 返回一个 Thread.Builder.OfVirtual,可以设置线程名,也可以选择创建后立即启动或先不启动:
public class VirtualThreadDemo {
public static void main(String[] args) throws InterruptedException {
Thread unstarted = Thread.ofVirtual()
.name("order-query")
.unstarted(() -> System.out.println("query order"));
unstarted.start();
unstarted.join();
Thread started = Thread.ofVirtual()
.name("payment-query")
.start(() -> System.out.println("query payment"));
started.join();
}
}如果你希望统一线程命名,或者把线程工厂交给框架使用,可以通过 ThreadFactory 创建虚拟线程:
import java.util.concurrent.ThreadFactory;
public class VirtualThreadDemo {
public static void main(String[] args) throws InterruptedException {
ThreadFactory factory = Thread.ofVirtual()
.name("worker-", 0)
.factory();
Thread thread = factory.newThread(() -> {
System.out.println(Thread.currentThread().getName());
});
thread.start();
thread.join();
}
}业务开发中最常见的是这种方式。它会为每个提交的任务创建一个新的虚拟线程:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class VirtualThreadDemo {
public static void main(String[] args) throws Exception {
try (ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor()) {
Future<String> future = executor.submit(() -> {
return "hello virtual thread";
});
System.out.println(future.get());
}
}
}这里的 ExecutorService 不是传统意义上的线程池。它不会维护一组固定虚拟线程来复用,而是每个任务一个新的虚拟线程。try-with-resources 结束时会调用 close(),等待已提交任务完成。
不要池化虚拟线程。
线程池的主要目标是复用昂贵的平台线程,并顺便限制并发。虚拟线程本身不是稀缺资源,池化它们通常没有意义,还会把“每个任务一个线程”的模型重新绕回旧思路。
如果你的真实目标是限制访问某个资源的并发量,应该限制资源,而不是限制虚拟线程数量。比如某个老系统最多只能承受 20 个并发请求,可以用 Semaphore 控制并发:
import java.util.concurrent.Semaphore;
public class OldServiceClient {
private static final Semaphore LIMIT = new Semaphore(20);
public String call() throws InterruptedException {
LIMIT.acquire();
try {
return doCall();
} finally {
LIMIT.release();
}
}
private String doCall() {
return "ok";
}
}如果瓶颈是数据库连接,那就调整连接池大小;如果瓶颈是下游接口限流,那就做限流、熔断和重试退避。虚拟线程能让等待变便宜,但不能让数据库连接、下游容量、CPU 和内存变无限。
先给结论:虚拟线程不是“跑得更快的线程”,而是“可以创建很多、阻塞成本更低的线程”。它通常能提升 I/O 密集型服务的吞吐,但不会降低一次数据库查询或一次 HTTP 调用本身的耗时。
下面这个例子模拟 10,000 个阻塞 1 秒的任务:
import java.time.Duration;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.stream.IntStream;
public class VirtualThreadCompareDemo {
public static void main(String[] args) {
long start = System.currentTimeMillis();
try (ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor()) {
IntStream.range(0, 10_000).forEach(i -> {
executor.submit(() -> {
Thread.sleep(Duration.ofSeconds(1));
return i;
});
});
}
System.out.println("cost: " + (System.currentTimeMillis() - start) + "ms");
}
}如果把它换成 Executors.newFixedThreadPool(200),同一时间最多只有 200 个任务在执行,10,000 个任务会被分批处理。按每批 1 秒粗略估计,总耗时接近 50 秒。虚拟线程版本可以让这 10,000 个任务几乎同时进入等待状态,平台线程在等待期间被释放出来,总耗时更接近单个任务的等待时间。
这个例子只能说明虚拟线程对“阻塞等待”友好,不是严谨基准测试。真实服务要看数据库连接池、HTTP 客户端连接池、下游限流、GC、对象分配、锁竞争、容器 CPU 配额等因素。
可以把虚拟线程的执行过程拆成三件事:调度、挂载/卸载、栈管理。
平台线程依赖操作系统调度。虚拟线程由 JDK 自己的调度器调度,再由平台线程承载执行。JEP 444 中说明,虚拟线程调度器是一个采用 FIFO 模式的 work-stealing ForkJoinPool,它和并行流使用的 common pool 不是同一个池。
默认情况下,调度器的并行度和可用处理器数量相关,可以通过下面的系统属性调整:
jdk.virtualThreadScheduler.parallelism:调度器目标并行度。jdk.virtualThreadScheduler.maxPoolSize:调度器可扩展的平台线程上限。
大多数业务系统不需要改这两个参数。优先排查连接池、限流、锁和阻塞点,通常比调整调度器参数更有效。
虚拟线程执行 Java 代码时,会挂载到某个平台线程上。遇到支持挂起的阻塞操作时,虚拟线程可以保存当前执行状态并卸载,平台线程继续服务其他虚拟线程。
常见的 JDK 阻塞操作已经为虚拟线程做了适配。例如网络 I/O、BlockingQueue、Future.get() 等,在虚拟线程中阻塞时通常不会长期占住底层平台线程。
不是所有阻塞都能卸载。JDK 21 到 JDK 23 中,虚拟线程在 synchronized 代码块或方法中阻塞,会出现 Pinning,也就是被固定在载体线程上。JDK 24 的 JEP 491 改进了这一点,使虚拟线程在 synchronized 中阻塞时也能释放底层平台线程,消除了绝大多数由 synchronized 带来的 Pinning 场景。调用 native 方法或 Foreign Function & Memory API 相关代码时,仍然要关注剩余的 Pinning 风险。
平台线程通常使用固定大小的操作系统线程栈。虚拟线程的栈以栈块对象的形式存放在 Java 堆中,可以随着执行过程增长和收缩。这也是虚拟线程能够大量创建的重要原因之一。
不过,这并不代表虚拟线程没有内存成本。每个虚拟线程仍然是对象,也有栈块、局部变量、ThreadLocal 等内存开销。百万级虚拟线程不是免费的,只是比百万级平台线程现实得多。
Pinning 可以理解为“虚拟线程暂时没法从载体线程上卸载”。虚拟线程被固定在某个平台线程上后,它在阻塞期间会连带占住底层操作系统线程,扩展性也会跟着变差。
在 JDK 21 到 JDK 23 中,最典型的 Pinning 场景是:虚拟线程在 synchronized 代码块或方法里执行阻塞 I/O。
public synchronized String load() throws IOException {
return remoteClient.get("/config"); // JDK 21-23 中,这里阻塞时可能固定载体线程
}短小、纯内存操作的 synchronized 问题不大。真正需要关注的是高频路径上持锁执行慢 I/O,例如持有对象锁时查数据库、调远程接口、读大文件。
如果你使用 JDK 21 到 JDK 23,可以考虑:
- 避免在
synchronized内部执行慢 I/O。 - 对高频阻塞锁场景使用
ReentrantLock,并用try/finally释放锁。 - 用 JFR 观察
jdk.VirtualThreadPinned事件。 - 临时使用
-Djdk.tracePinnedThreads=full定位被固定的调用栈。
如果你使用 JDK 24 或更高版本,synchronized 导致的主要 Pinning 问题已经被 JEP 491 解决。选择 synchronized 还是 java.util.concurrent.locks,可以重新回到代码语义、可维护性和锁能力本身来判断。
虚拟线程提升的是等待型任务的并发承载能力。CPU 密集型任务最终还是要抢 CPU 时间片,虚拟线程数量再多也不能突破 CPU 核心数的物理限制。
不要创建固定数量的虚拟线程池。需要限制并发时,用 Semaphore、连接池、限流器或队列容量限制具体资源。
Java 21 正式版保证虚拟线程支持 ThreadLocal,这有利于兼容老代码和框架。但不要用 ThreadLocal 给每个虚拟线程缓存大对象。
以前在线程池里,一个 ThreadLocal<SimpleDateFormat> 可能只对应几十或几百个平台线程。迁移到虚拟线程后,如果每个任务一个虚拟线程,同样的写法可能变成每个任务创建一份缓存对象,内存和分配压力会被放大。
如果只是传递请求上下文、用户 ID、Trace ID,通常问题不大。如果是缓存数据库连接、大数组、复杂 formatter、客户端对象,就要重新评估。JDK 25 通过 JEP 506 将 Scoped Values 转正,它更适合在大量虚拟线程之间传递不可变上下文。
虚拟线程让创建线程更便宜,也意味着你更容易同时跑起大量并发任务。原来因为线程池较小而没暴露的数据竞争,切到虚拟线程后可能更容易出现。
需要继续遵守并发编程的基本规则:共享可变状态要加锁或隔离,数据库连接、会话对象、非线程安全客户端不要被多个虚拟线程同时乱用。
很多服务迁移到虚拟线程后,第一个瓶颈不再是业务线程池,而是数据库连接池、HTTP 连接池、Redis 连接数或下游限流。
这不是虚拟线程的问题。虚拟线程只是让更多任务有机会同时推进,真正的共享资源仍然要按容量管理。压测时建议同时观察:
- 应用 QPS、响应时间和错误率。
- 数据库连接池活跃连接、等待队列和超时数。
- HTTP 客户端连接池和下游 429/5xx。
- CPU、堆内存、GC、对象分配速率。
- JFR 中的虚拟线程事件和锁竞争。
虚拟线程最适合同步阻塞代码。已经用 Reactive/WebFlux/Netty 写成全链路异步的系统,不一定能因为打开虚拟线程就获得明显收益。
更麻烦的是混用模型:外层虚拟线程,内层又大量使用异步回调和线程池,排查时可能同时面对虚拟线程、事件循环、业务线程池、连接池几套上下文。迁移时最好先挑同步阻塞链路试点,而不是全系统一键替换。
Spring Boot 3.2 开始提供了比较直接的开关。使用 Java 21 或更高版本时,可以在配置中开启:
spring.threads.virtual.enabled=trueSpring Boot 官方文档还提到几个实践点:
- 开启虚拟线程后,配置传统线程池大小的部分属性不再按原来的方式生效,因为虚拟线程调度依赖 JVM 范围内的平台线程池。
- 虚拟线程是守护线程。如果应用依赖
@Scheduled等后台任务保持 JVM 存活,建议设置spring.main.keep-alive=true。 - Spring Boot 官方目前建议 Java 24 或更高版本获得更好的虚拟线程体验,主要和 Pinning 改进有关。
一个简单配置如下:
spring:
threads:
virtual:
enabled: true
main:
keep-alive: true开启之后,不代表所有接口都会变快。它更可能改善的是同步阻塞、I/O 等待明显、并发较高的接口。如果接口主要耗在 CPU、锁竞争、慢 SQL 本身或下游限流上,虚拟线程只能让问题更早暴露。
JDK 已经为虚拟线程补了不少观测能力。
传统 jstack 面对成千上万个虚拟线程时不太合适。JDK 提供了新的线程转储能力:
jcmd <pid> Thread.dump_to_file -format=json thread-dump.json也可以导出文本格式:
jcmd <pid> Thread.dump_to_file -format=text thread-dump.txtJSON 格式更适合工具分析,尤其是虚拟线程数量很多时。
JFR 中和虚拟线程相关的事件包括:
jdk.VirtualThreadStartjdk.VirtualThreadEndjdk.VirtualThreadPinnedjdk.VirtualThreadSubmitFailed
其中 jdk.VirtualThreadPinned 对排查 Pinning 很有用。JDK 24 以后,synchronized 相关 Pinning 大多被解决,但 native/FFM 等剩余场景仍然可以通过 JFR 观察。
在 JDK 21 到 JDK 23 中,可以临时使用:
-Djdk.tracePinnedThreads=full它会在虚拟线程阻塞且被固定时打印调用栈,适合本地或测试环境定位问题。JDK 24 的 JEP 491 之后,synchronized 相关的主要 Pinning 场景已经改进;native/FFM 等剩余边界仍然建议结合 JFR 和线程转储判断。
平台线程通常和操作系统线程一一对应,创建和上下文切换成本较高,数量有限。虚拟线程由 JDK 调度,可以把大量虚拟线程映射到少量平台线程上。虚拟线程阻塞等待 I/O 时,通常可以从载体线程卸载,让平台线程继续执行其他虚拟线程。
I/O 密集型任务大部分时间在等待外部资源。平台线程等待时会占住操作系统线程;虚拟线程等待时可以挂起自己并释放载体线程。这样同样数量的平台线程可以承载更多并发任务。
不适合把它当作 CPU 提速工具。CPU 密集型任务需要真实 CPU 时间,线程数超过核心数后只会增加调度竞争。虚拟线程能改善高并发等待,不会让单个计算任务更快。
不需要,也不建议。虚拟线程便宜,应该按任务创建。需要限制并发时,限制具体资源,比如数据库连接池、HTTP 连接池、Semaphore、限流器,而不是池化虚拟线程。
它们都属于轻量级并发的思路,但 Java 虚拟线程是 java.lang.Thread 的实现,纳入了 Java 原有线程模型。业务代码不需要写 async/await,也不需要手动 yield。和 Go goroutine 相比,虚拟线程更强调兼容 Java 既有线程 API、调试工具和阻塞式代码风格。对开发者来说,它更像“便宜很多的线程”。
看场景。很多同步阻塞的服务端接口可以用虚拟线程获得更好的可读性和足够的吞吐,不必为了释放线程写复杂回调链。但 Reactive 仍然适合流式处理、背压、事件驱动、长连接和已经全链路异步化的系统。虚拟线程不是替代所有异步模型的银弹。
可以用,但要注意边界。JDK 21 到 JDK 23 中,虚拟线程在 synchronized 内部执行阻塞操作可能出现 Pinning。短小的内存同步问题不大,高频路径上不要持有 synchronized 锁执行慢 I/O。JDK 24 通过 JEP 491 改进后,synchronized 相关 Pinning 已经基本解决。
- JEP 444: Virtual Threads
- Oracle Java 21 Documentation: Virtual Threads
- JEP 491: Synchronize Virtual Threads without Pinning
- JEP 506: Scoped Values
- Spring Boot Reference Documentation: Virtual threads
- Spring Blog: Embracing Virtual Threads
- Inside Java: Managing Throughput with Virtual Threads
- Quarkus Blog: When Quarkus meets Virtual Threads