|
259 | 259 | - 对于`ReLu`函数来说:,所以不可能均值为0 |
260 | 260 | - `w`满足对称区间的分布,并且偏置,所以也满足对称区间的分布,所以: |
261 | 261 | ![enter description here][25]..........................................(4) |
262 | | -- 将(4)代入(3)中得: |
| 262 | +- 将上式`(4)`代入`(3)`中得: |
263 | 263 | ![$$Var[{y_l}] = {1 \over 2}{n_l}Var[{w_l}]Var[{y_{l - 1}}]$$](http://latex.codecogs.com/gif.latex?%5Cfn_cm%20%24%24Var%5B%7By_l%7D%5D%20%3D%20%7B1%20%5Cover%202%7D%7Bn_l%7DVar%5B%7Bw_l%7D%5DVar%5B%7By_%7Bl%20-%201%7D%7D%5D%24%24).......................................................(5) |
264 | 264 | - 所以对于`L`层: |
265 | 265 | ![$$Var[{y_L}] = Var[{y_1}]\prod\limits_{l = 2}^L {{1 \over 2}{n_l}Var[{w_l}]} $$](http://latex.codecogs.com/gif.latex?%5Cfn_cm%20%24%24Var%5B%7By_L%7D%5D%20%3D%20Var%5B%7By_1%7D%5D%5Cprod%5Climits_%7Bl%20%3D%202%7D%5EL%20%7B%7B1%20%5Cover%202%7D%7Bn_l%7DVar%5B%7Bw_l%7D%5D%7D%20%24%24).....................................................................(6) |
266 | | - - 从上式可以看出,因为**累乘**的存在,若是![$${1 \over 2}{n_l}Var[{w_l}] < 1$$](http://latex.codecogs.com/gif.latex?%5Cfn_cm%20%24%24%7B1%20%5Cover%202%7D%7Bn_l%7DVar%5B%7Bw_l%7D%5D%20%3C%201%24%24),每次累乘都会使方差缩小,若是大于1,每次会使方差当大。 |
| 266 | + - 从上式可以看出,因为**累乘**的存在,若是![$${1 \over 2}{n_l}Var[{w_l}] < 1$$](http://latex.codecogs.com/gif.latex?%5Cfn_cm%20%24%24%7B1%20%5Cover%202%7D%7Bn_l%7DVar%5B%7Bw_l%7D%5D%20%3C%201%24%24),每次累乘都会使方差缩小,若是大于`1`,每次会使方差当大。 |
267 | 267 | - 所以我们希望: |
268 | 268 | ![$${1 \over 2}{n_l}Var[{w_l}] = 1$$](http://latex.codecogs.com/gif.latex?%5Cfn_cm%20%24%24%7B1%20%5Cover%202%7D%7Bn_l%7DVar%5B%7Bw_l%7D%5D%20%3D%201%24%24) |
269 | | -- 所以**初始化方法**为:是`w`满足**均值为0**,**标准差**为的**高斯分布**,同时**偏置**初始化为0 |
270 | | -### 3、 |
| 269 | +- 所以**初始化方法**为:是`w`满足**均值为0**,**标准差**为的**高斯分布**,同时**偏置**初始化为`0` |
| 270 | + |
| 271 | + |
| 272 | +### 3、反向传播推导 |
| 273 | +- ....................................................(7) |
| 274 | + - 假设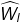和相互独立的 |
| 275 | + - 当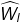初始化Wie对称区间的分布时,可以得到:的**均值**为0 |
| 276 | + - `△x,△y`都表示梯度,即: |
| 277 | + , |
| 278 | +- 根据**反向传播**: |
| 279 | + |
| 280 | + - 对于`ReLu`函数,**f的导数**为`0`或`1`,且**概率是相等的**,假设和是相互独立的, |
| 281 | + - 所以:![$$E[\Delta {y_l}] = E[\Delta {x_{l + 1}}]/2 = 0$$](http://latex.codecogs.com/gif.latex?%5Cfn_cm%20%24%24E%5B%5CDelta%20%7By_l%7D%5D%20%3D%20E%5B%5CDelta%20%7Bx_%7Bl%20+%201%7D%7D%5D/2%20%3D%200%24%24) |
| 282 | +- 所以:![$$E[{(\Delta {y_l})^2}] = Var[\Delta {y_l}] = {1 \over 2}Var[\Delta {x_{l + 1}}]$$](http://latex.codecogs.com/gif.latex?%5Cfn_cm%20%24%24E%5B%7B%28%5CDelta%20%7By_l%7D%29%5E2%7D%5D%20%3D%20Var%5B%5CDelta%20%7By_l%7D%5D%20%3D%20%7B1%20%5Cover%202%7DVar%5B%5CDelta%20%7Bx_%7Bl%20+%201%7D%7D%5D%24%24)...................................................(8) |
| 283 | +- 根据`(7)`可以得到: |
| 284 | +![enter description here][26] |
| 285 | +- 将`L`层展开得: |
| 286 | +![$$Var[\Delta {x_2}] = Var[\Delta {x_{L + 1}}]\prod\limits_{l = 2}^L {{1 \over 2}\widehat {{n_l}}Var[{w_l}]} $$](http://latex.codecogs.com/gif.latex?%5Cfn_cm%20%24%24Var%5B%5CDelta%20%7Bx_2%7D%5D%20%3D%20Var%5B%5CDelta%20%7Bx_%7BL%20+%201%7D%7D%5D%5Cprod%5Climits_%7Bl%20%3D%202%7D%5EL%20%7B%7B1%20%5Cover%202%7D%5Cwidehat%20%7B%7Bn_l%7D%7DVar%5B%7Bw_l%7D%5D%7D%20%24%24)...........................................................(9) |
| 287 | +- 同样令:![$${1 \over 2}\widehat {{n_l}}Var[{w_l}] = 1$$](http://latex.codecogs.com/gif.latex?%5Cfn_cm%20%24%24%7B1%20%5Cover%202%7D%5Cwidehat%20%7B%7Bn_l%7D%7DVar%5B%7Bw_l%7D%5D%20%3D%201%24%24) |
| 288 | + - 注意这里:,而 |
| 289 | + |
| 290 | +- 所以应满足**均值为0**,**标准差**为:的分布 |
| 291 | + |
| 292 | +### 4、正向和反向传播讨论、实验和**PReLu**函数 |
| 293 | +- 对于**正向和反向**两种初始化权重的方式都是可以的,论文中的模型都能够**收敛** |
| 294 | +- 比如利用**反向传播**得到的初始化得到:![$$\prod\limits_{l = 2}^L {{1 \over 2}\widehat {{n_l}}Var[{w_l}]} = 1$$](http://latex.codecogs.com/gif.latex?%5Cfn_cm%20%24%24%5Cprod%5Climits_%7Bl%20%3D%202%7D%5EL%20%7B%7B1%20%5Cover%202%7D%5Cwidehat%20%7B%7Bn_l%7D%7DVar%5B%7Bw_l%7D%5D%7D%20%3D%201%24%24) |
| 295 | +- 对应到**正向传播**中得到: |
| 296 | +![enter description here][27] |
| 297 | + |
| 298 | +- 所以也不是逐渐缩小的 |
| 299 | +- 实验给出了与**第一篇论文**的比较,如下图所示,当神经网络有30层时,**Xavier初始化权重**的方法(第一篇论文中的方法)已经不能收敛。 |
| 300 | +![enter description here][28] |
| 301 | +- 对于**PReLu激励函数**可以得到:![$${1 \over 2}(1 + {a^2}){n_l}Var[{w_l}] = 1$$](http://latex.codecogs.com/gif.latex?%5Cfn_cm%20%24%24%7B1%20%5Cover%202%7D%281%20+%20%7Ba%5E2%7D%29%7Bn_l%7DVar%5B%7Bw_l%7D%5D%20%3D%201%24%24) |
| 302 | + - 当`a=0`时就是对应的**ReLu激励函数** |
| 303 | + - 当`a=1`是就是对应**线性函数** |
| 304 | + |
| 305 | + |
| 306 | +--------------------------------------------------------------------- |
| 307 | + |
| 308 | +## 四、Batch Normalization(BN)批标准化 |
| 309 | +### 1、概述 |
| 310 | +### 2、`BN`思路 |
| 311 | +### 3、`BN`网络的训练和推断 |
| 312 | +### 4、实验 |
| 313 | + |
271 | 314 |
|
272 | 315 |
|
273 | 316 |
|
|
324 | 367 | [22]: ./images/Weights_initialization_06.png "Weights_initialization_06.png" |
325 | 368 | [23]: ./images/Weights_initialization_07.png "Weights_initialization_07.png" |
326 | 369 | [24]: ./images/Weights_initialization_08.png "Weights_initialization_08.png" |
327 | | - [25]: ./images/Weights_initialization_09.png "Weights_initialization_09.png" |
| 370 | + [25]: ./images/Weights_initialization_09.png "Weights_initialization_09.png" |
| 371 | + [26]: ./images/Weights_initialization_10.png "Weights_initialization_10.png" |
| 372 | + [27]: ./images/Weights_initialization_11.png "Weights_initialization_11.png" |
| 373 | + [28]: ./images/Weights_initialization_12.png "Weights_initialization_12.png" |

0 commit comments