
Skip to main content
DATA DIFFS
What's a Data Diff?
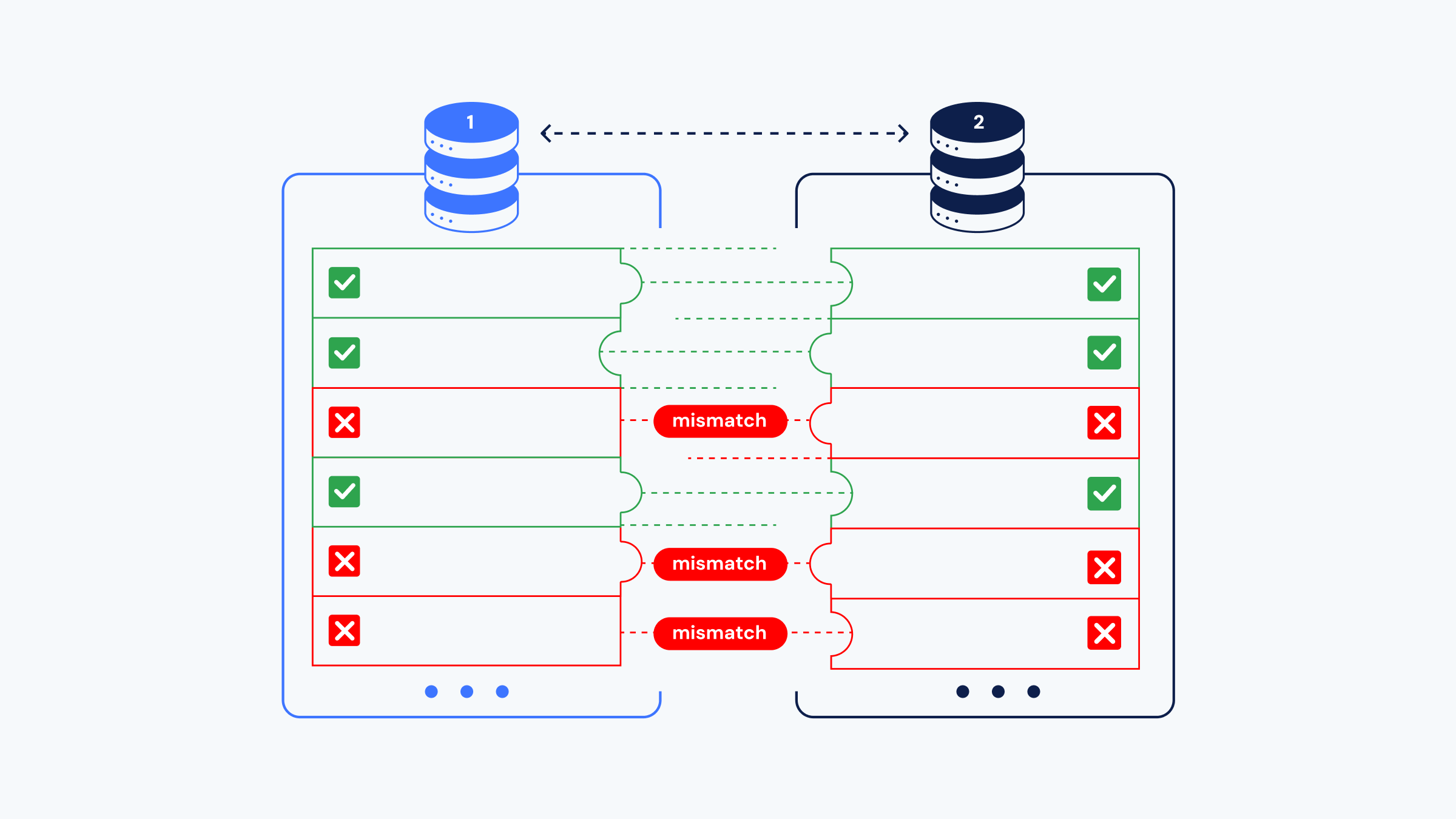
A data diff is the value-level comparison between two tables, used to identify critical changes to your data and guarantee data quality.
When you git diff your code, you’re comparing two versions of your code files to see what has changed, such as lines added, removed, or modified. Similarly, a data diff compares two versions of a dataset or two databases to identify differences in individual cells in the data.
Why do I need to diff data?
Just as diffing code and text is fundamental to software engineering and working with text documents, diffing data is essential to the data engineering workflow. Why? In data engineering, both data and the code that processes it are constantly evolving. Without the ability to easily diff data, understanding and tracking data changes becomes challenging. This slows down the development process and makes it harder to ensure data quality. There is a lot you can do with data diff:- Test SQL code by comparing development or staging environment data to production
- Compare tables in source and target systems to identify discrepancies when migrating data between databases
- Detect value-level outliers, or unexpected changes, in data flowing through your ETL/ELT pipelines
- Verify that reports generated for regulatory compliance accurately reflect the underlying data by comparing report outputs with source data
Why Datafold?
Data diffing is a fundamental capability in data engineering that every engineer should have access to. Datafold’s Data Diff compares datasets fast, within or across databases. As part of Datafold’s data quality power tools, Data Diff is fully interoperable with AI agents via MCP — so your coding agents can run diffs, validate their own work, and reconcile data across sources programmatically. Datafold offers an enterprise-ready solution for comparing datasets at scale, with comprehensive diffing, API access, and secure deployment options. Here’s how you can identify row-level discrepancies in Datafold:- Automated and collaborative diffing and testing for data transformations in CI
- Data diffing informed by column-level lineage, and validation of code changes with visibility into BI applications
- Validating large data migrations or continuous replications with automated cross-database diffing capabilities
Three ways to learn more
If you’re new to Datafold or data diffing, here are three easy ways to get started:- Explore our CI integration guides: See how Datafold fits into your continuous integration (CI) pipeline by checking out our guides for No-Code, API, or dbt integrations.
- Try it yourself: Use your own data with our 14-day free trial and experience Datafold in action.
- Book a demo: Get a deeper technical understanding of how Datafold integrates with your company’s data infrastructure by booking a demo with our team.
Previous
How Datafold Diffs DataData diffs allow you to perform value-level comparisons between any two datasets within the same database, across different databases, or even between files.
Next