
Bayan Project
What is Bayan project about?
Aim
- Developing a reliable and accurate algorithm for descriptive community detection in small and mid-sized networks, with optimality guarantees.
Community Detection
-
Descriptive community detection is the process of clustering the nodes of a network (graph) based on the structural patterns. It is an unsupervised task with a wide range of applications in life sciences (e.g., biological systems), social sciences (offline/online social networks), physical sciences (VLSI design, complex systems), mathematical sciences (agent-based models, computer vision), and even health sciences (drug discovery) (Wikipedia).
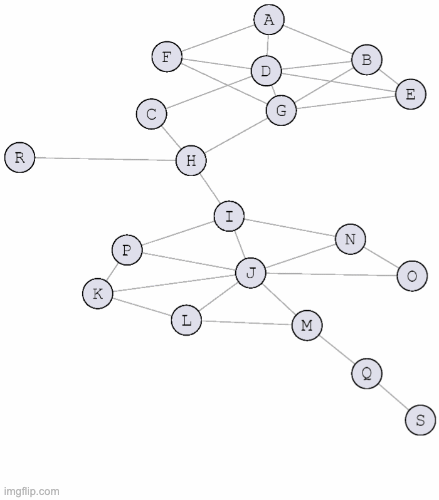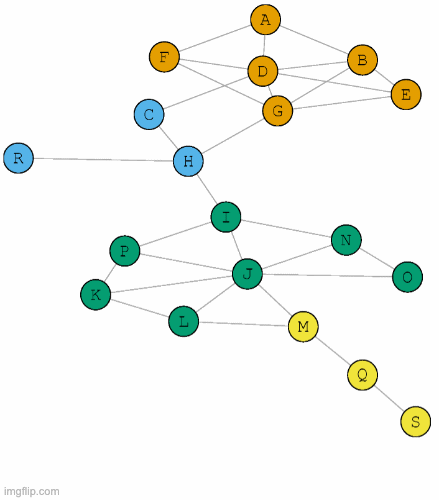
- There are several existing methods (algorithms) for approaching this computational problem. One family of algorithms attempts to find communities by maximizing modularity: a network-level quantity indicating the fraction of intra-community edges minus the expected fraction under a degree-preserving null model.
Do we need yet another community detection algorithm? Yes, and here's why:
-
In the first part of this project, we solved the following exact Integer Programming (IP) model for a testbed of over 100 real and random networks with reasonably modular structures. We evaluated nine existing modularity-based community detection methods, CNM (Greedy), Louvain, Combo, Belief, Leiden, Paris, EdMot, Leicht Newman (LN), and Graph neural network (GNN).
-
We investigated the extent to which current modularity-based heuristics succeeds in maximizing modularity by evaluating
(1) the ratio of their output modularity to the maximum modularity for a given graph (GOP) and
(2) the similarity between their output partition and all modularity-maximizing partitions of that graph using Adjusted Mutual Information (AMI).
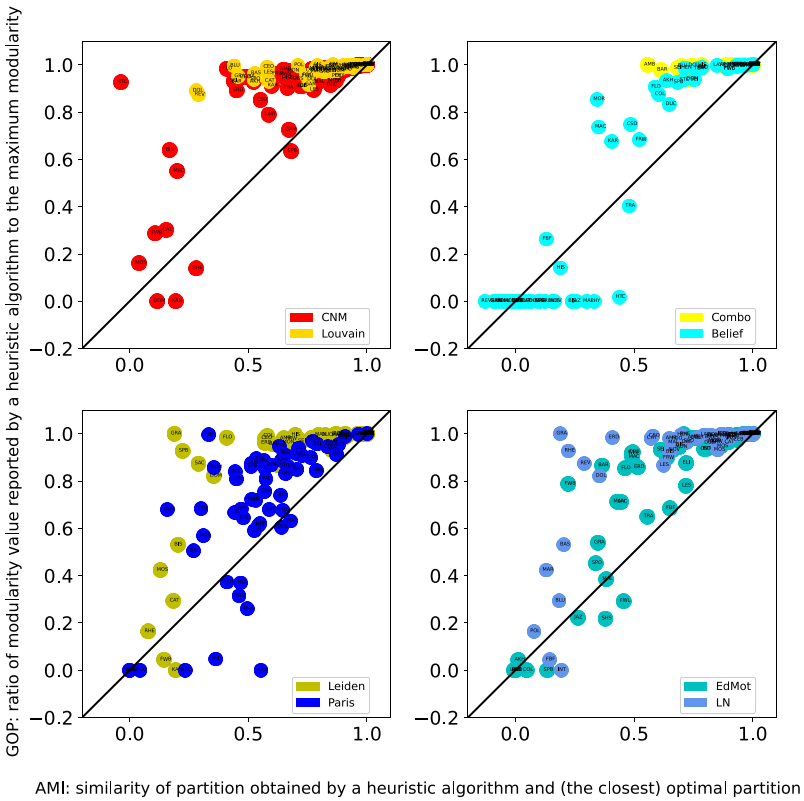
The following figure shows a scatterplot of GOP on the y-axis and AMI on the x-axis for each algorithm (and their variations).
- Looking at the y-axis values in the figure, we observe that there is a substantial variation in the values of GOP (i.e., extent of sub-optimality) returned by the nine heuristic algorithms. The x-axis values in the figure show the considerable dissimilarity between the sub-optimal partitions and any optimal partition for these networks. Focusing on the position of data points, we observe that they are mostly located above their corresponding 45-degree line. This indicates that sub-optimal partitions tend to be disproportionally dissimilar to any optimal partition. This result goes against the naive viewpoint that close-to-maximum modularity partitions are also close to an optimal partition.
- The average modularity-based heuristic algorithm returns optimal partitions for only 43.9% of these reasonably modular networks. Taken together with the low success rates of heuristic algorithms in maximizing modularity, our results indicate a crucial mismatch between the design philosophy of modularity maximization heuristics for community detection and their performance: Heuristic modularity maximization algorithms rarely return an optimal partition or a partition resembling an optimal partition, even on networks with a reasonably modular structure.
- The Bayan algorithm solves this fundamental problem and provides optimal partitions and partitions within a guaranteed proximity to an optimal partition (exact solutions and approximate solutions for modularity maximization).
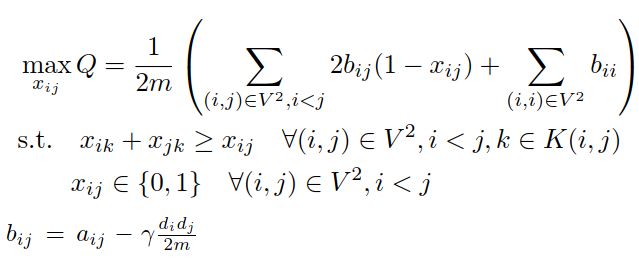
Notation for the IP model: The input is graph G=(V,E) with |V|=n nodes, |E|=m edges, and adjacency matrix entries a_{ij}. d_i is the degree of node i, gamma is the resolution parameter. The term associated with each pair (i,j) is b_{ij} and referred to as the modularity matrix entry for (i,j). Using the binary decision variable x_{ij} for each pair of distinct nodes (i,j), their cluster membership is either the same (represented by x_{ij}=0) or different (represented by x_{ij}=1). K(i,j) indicates a minimum-cardinality separating set for the nodes i,j. Accordingly, the problem of maximizing the modularity of input graph G can be formulated as the IP model above (Dinh and Thai 2015).
How does Bayan compare with other community detection methods w.r.t. retrieving planted partitions?
- In the second part of this project, we compared 30 community detection methods in a testbed of structurally diverse and randomly generated LFR and ABCD benchmark graphs. We do not assume that modularity is a silver bullet for community detection. Regardless of using modularity or other approaches, community detection methods can be compared based on their capability in retrieving the ground-truth communities (a.k.a. planted partitions) of LFR and ABCD benchmark graphs using AMI. We generate LFR and ABCD graphs with different values for the mixing parameter (fraction of inter-community edges). Increasing the mixing parameter (mu) increases the disassociation of the structure and ground-truth communities.
- This short animation shows an ABCD benchmark graph which was generated using a small mixing parameter. The (ground-truth) planted partition is shown by the node colors in the animation. In this standard retrieval test (based on LFR or ABCD benchmarks), each algorithm take the uncolored graph and clusters the nodes based on the structure. The algorithm whose partition is more similar to the planted partition is going to have a higher AMI and therefore a better rank compared to other algorithms.
-
We evaluated the AMI between the ground-truth planted partitions and the partitions returned from each algorithm,
Greedy (CNM),
Louvain,
Combo,
Belief,
Leiden,
Paris,
CPM,
Chinese whispers,
EdMot,
Genetic Algorithm (GA),
Gemsec,
Infomap,
k-cut,
asynchronous label propagation,
semi-synchronous label propagation,
Walktrap,
Reichardt Bornholdt with Erdos-Renyi (RB),
Reichardt Bornholdt with configuration model (LN),
Significant scales,
Surprise,
Weighted Community Clustering (WCC),
Kernighan-Lin bisection,
Diffusion Entropy Reduced (DER),
Markov stability with random selection,
Markov stability with minimum NVI,
Stochastic Block Model (SBM),
SBM with Markov chain Monte Carlo (MCMC),
Bayesian Planted Partition (BPP), and
BPP with MCMC.
-
For the two Markov stability algorithms (MR and MV), we have used the PyGenStability library (version 0.2.2). For the four inferential methods (SB, SM, BP, and BM), we have used the graph_tool library (version 2.57). For the two algorithms, Kernighan-Lin and asynchronous label propagation, we have used the NetworkX library (version 3.1). For the remaining 21 algorithm, we have used the Community Discovery library (CDlib) (version 0.2.6).
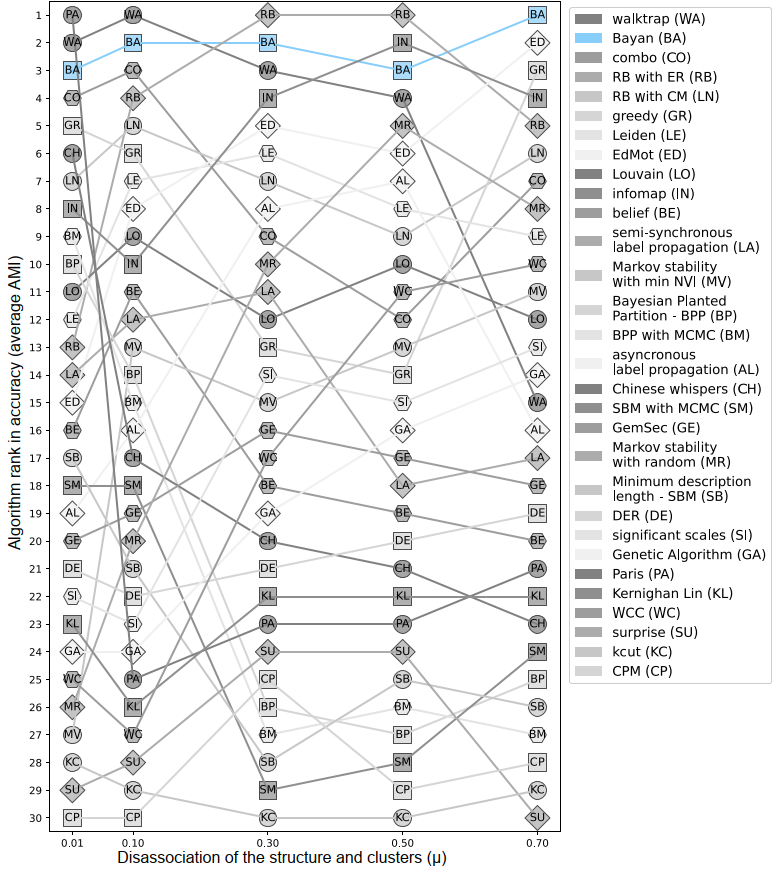
- The figure above ranks the 30 algorithms based on AMI in five experiment settings (each with a specific mu parameter value) averaged over 100 LFR graphs.
- Bayan has a relatively high and stable performance rank over different values of the mu parameter. These results reaffirm that the practical relevance of modularity as an objective function, despite its theoretical flaws, is yet to be challenged by a practical method that is more accurate and stable. The descriptive ranking results are validated by rigorous statistical tests on the performance of the algorithms (read the Bayan preprint for more info).
Interested to learn more? Check out our three peer-reviewed papers below.
- Samin Aref, Mahdi Mostajabdaveh, and Hriday Chheda. "Heuristic modularity maximization algorithms for community detection rarely return an optimal partition or anything similar." in Computational Science - ICCS 2023, LNCS 10476, Springer, 2023 doi.org/10.1007/978-3-031-36027-5_48 Preprint
- Samin Aref and Mahdi Mostajabdaveh. "Analyzing modularity maximization in approximation, heuristic, and graph neural network algorithms for community detection." Journal of Computational Science, 2024 doi.org/10.1016/j.jocs.2024.102283 Preprint
- Samin Aref, Mahdi Mostajabdaveh, and Hriday Chheda. "The Bayan algorithm: detecting communities in networks through exact and approximate optimization of modularity." Physical Review E, 2024 Preprint
- The Bayan algorithm is publicly available through the package installer for Python (pip) .
-
Resources for the Bayan algorithm in Python:
- Minimal working examples of Bayan in Google Colab
- Bayan GitHub Repository
- Bayan library on pypi
- Running Bayan for optimization models with more than 2000 variables or constraints (input graphs with more than 44 nodes) requires a free academic license to be installed for the mathematical solver Gurobi (which solves the linear programming relaxation problems within the Bayan algorithm). You may follow the instructions in the GitHub Repository to request and install a free academic license for Gurobi if your usage is not commercial and you are affiliated with an academic institution.
- The Bayan algorithm can be used as follows in Jupyter Python:
- Bayan is a village in the Southeast of Iran located at the midpoint of the hometowns of the developers of this project.
- Bayan is a small "community" of 22 people in 5 families as of the 2016 census.
You can start using Bayan in Python today.

Project Members

Prof. Samin Aref
Department of Mechanical & Industrial Engineering, University of Toronto




Mahdi Mostajabdaveh, Ph.D.
Department of Mathematical & Industrial Engineering, Polytechnique Montreal

Hriday Chheda
Department of Mechanical & Industrial Engineering, University of Toronto
Origin of the algorithm name "Bayan"?

Acknowledgments

The Bayan project is supported by the Data Sciences Institute at the University of Toronto.